![]()

![]()
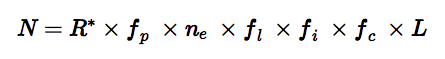
中学生の頃、カール・セーガン博士のコスモスを本で読むのも、テレビで見るのも大好きだった。10回以上は確実に本を読んだはずだ。そして、テレビシリーズが地元のPBS局で放映される度にテレビにかじりついていた記憶がある。
コスモスで一番記憶に残っているパートは、ドレイクの方程式だ:
ドレイクの方程式は、銀河系の地球外生命体の数を推測する方法であり、(惑星を持つ星の割合f(p)や生命体を維持することが可能な惑星の割合f(l)等)パラメータに分類し、その後、まとめて掛けることで算出する。
セーガン博士がドレイクの方程式を説明する動画をユーチューブで視聴することが出来る。セーガン博士は悲観的にNを10と決めるものの(80年代前半はあまりよい時代ではなかった)、1分後には“数百万”にアップグレードしていた(短期記憶もまたいまいちであった)。
数週間前にSMX イーストで誰かと話していたとき、オーガニック検索のコンバージョンの計測が、次のようにドレイクの方程式と同じように表現することが出来ることに気づいた:
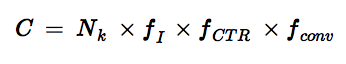
この方程式では、Cはコンバージョンの数であり、N(k)はキーワードを検索している人の数(またはキーワードのグループ)、f(I)は自分のサイトのリンクが表示されている検索が表示される割合(インプレッションとも呼ばれる)、f(CTR)は検索エンジンの結果のクリックスルー率、そして、f(conv)はクリックした後にコンバートする人の割合を示す*。
そして、注目の多くは次の3つの要素に振り分けられると思った: N(k)はキーワードのリサーチに、f(I)はSEOの主要な目標、そして、f(conv)はユーザビリティとグラフィックデザインの領域だ。
クリックスルー率の改善はその他の要因の効果を倍増させるにも関わらず、その他の三つの用語と比べ、クリックスルー率に寄せられる注目、または最適化は軽視されがちである。CTRに影響を与える要因の大半は、直接コントロールすることが可能である点、そして、ウェブサイトのユーザビリティに全く影響を与えない点を考慮すると、奇妙と言わざるを得ない。
そのため、オーガニックの検索からユーザーをコンバートする要因として十分に活用されているものの、過小評価されていおり、しかも直接管理することが出来るアイテムと考えるなら、CTRに影響与えることが可能な様々な方法を詳しく調べ、コラムを1つや2つ綴る価値はあるはずである。
この記事の残りは、検索結果のタイトルとスニペット、そして、この2つがクリックスルー率に影響を与える仕組みの説明に割く。来月のコラムでは、もっと多くのポイントを説明する予定だ。
検索結果の基本的な構成要素は、バネッサ・フォックス氏が綴った記事で網羅されているので、気分を切り替えたいなら、もしくは用語の幾つかがよく分からないなら、目を通してもらいたい。

典型的な検索エンジンの結果の最も分かりやすく、そして、最も大きい構成要素は、タイトルとスニペットである。タイトルは、通常、ページのHTMLタイトルタグが採用される。スニペットは、複数のソースから採用されるが、巧みに綴られたメタデスクリプションタグから採用されるのが理想である。
タイトルタグとメタデスクリプションは、通常、ブラウザで閲覧する際は見えない点に注意してもらいたい(開くタブの数が多い場合は尚更)。この2つの要素は、検索エンジンの結果に大きな影響を与えるが、注意していないと思わぬしっぺ返しに遭うので気をつけよう。
上の例のスニペットは質が高い。よく説明されており、その結果、私はクリックして、ドレイクの方程式の記憶を手繰り寄せたのだ。
しかし、私がソースコードをチェックして、スニペットがメタデスクリプションから採用されたかどうかを確認しようとすると、次のコードが出てきた:
![]()
つまり、タイトルはページから直接抜粋されているものの、メタデスクリプションは明らかに異なる。これはページのテンプレートの残されたボイラープレートテキストである。このテキストはサイトの様々な場所で掲載されているため、ページのコンテンツとは明らかに関係ないため、そして、あまりにも短く過ぎるため、グーグルはページ上のスニペットをこの結果のために生成した。
通常、これは良い結果とは言えない。だからこそ各ページのメタデスクリプションに注意する必要があるのだ。以下に同じクエリのその他の結果を幾つか掲載する。ページの内容が伝わってくるメタデスクリプションは一つもない:
コンピュータにアドワーズの広告を書いてもらっても、コンピュータにサイトのスニペットを作らせるのは避けるべきである。
クライアントのために評価するサイトの中で、タイトルとメタデスクリプションが重複していたためにグーグルやビングに無視されるサイトは多い。そのため、それぞれのページにこの2つのアイテムを作成することが肝要だ。
リッチスニペットに関するSMX イーストのセッションで、グーグルのジャック・メンゼル氏は、グーグルが検索結果でタイトルを無効にするその他の理由を挙げていた:
メンゼル氏は、グーグルはユーザーの役に立つ場合のみタイトルを修正すると慎重に指摘していたが、ページが検索結果に表示される仕組みを出来るだけ自分で管理しておきたいところだ。
タイトルと生成されるスニペットが同じケースも重複の問題点の一つである。このケースが発生すると、グーグルは1つの結果のみを表示し、残りを抑制する。そして、以下のメッセージを検索結果の下に掲載する:

これは、クエリに対してランクインしているページがあるにも関わらず、グーグルがその他のランクインしているページと区別することが出来ないために表示してもらえない点を指摘する憂鬱なメッセージだ(このメッセージは、サイトのページネーションに問題がある点を示唆する可能性があり、その場合はしかるべき対応が必要である)。
ユーザーが検索結果に目を通し、クリックするサイトを決める際、じっくりと腰を落ち着けて、ワインを片手にユリシーズを読み、古典について深く考えを巡らすと言うよりも、猿が果物を探して木を見渡すような行動を取る。
つまり、検索者は記憶の中に存在するキーワードをスキャンしているのか、もしくは“一部の人達のセオリーによると”キーワードの全体の形をスキャンしているのだ。
この見解と、この指摘やこの指摘やこの指摘のように、典型的な検索エンジンの結果ページ上に残される視線追跡調査を組み合わせると、重要なキーワードはモンキースキャナー達に見てもらえる可能性の高いタイトルの冒頭に配置するべきだと言う結論に達する。
(キーワードを左側に配置するアイデアを否定する議論を耳にしたことがあるが、私よりも心理学にのめり込んでいる人達にこの議論は任せておこうと思う)
無数のページを持つサイトにおいては、一つ一つ固有で、意義深いタイトルを作成する戦略は現実的ではない。
ページに関するアイテムに対するメタデータを使って、クリックスルーを強く促すような方法で自動生成しても問題はない。
以下に先日私が見かけたタイトルの例を掲載する:

私がウィロウグレンで家を探していたなら、この結果をクリックしたくなっていたはずだ。アプリケーションデータベースで自動的に生成された点は明白だが、固有であり、クリックスルーを促すことが考慮されている。
今後のコラムでは、URL、ブレッドクラム、構造化されたメタデータ、アンカー、ソーシャルシグナル、文字コード、月の相等、クリックスルー率に影響を与えるその他の要因を取り上げていく予定だ。
*このエントリを書き終えた後、バネッサ・フォックス氏が綴った書籍「マーケティング・イン・ジ・エイジ・オブ・グーグル」で紹介されているサーチャーペルソナのワークフローに似ていることに気づいた。さらにこの概念を詳しく知りたいなら、この書籍を読んでもらいたい。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「The Clickthrough Rate Equation In Organic Search」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









