![]()

![]()

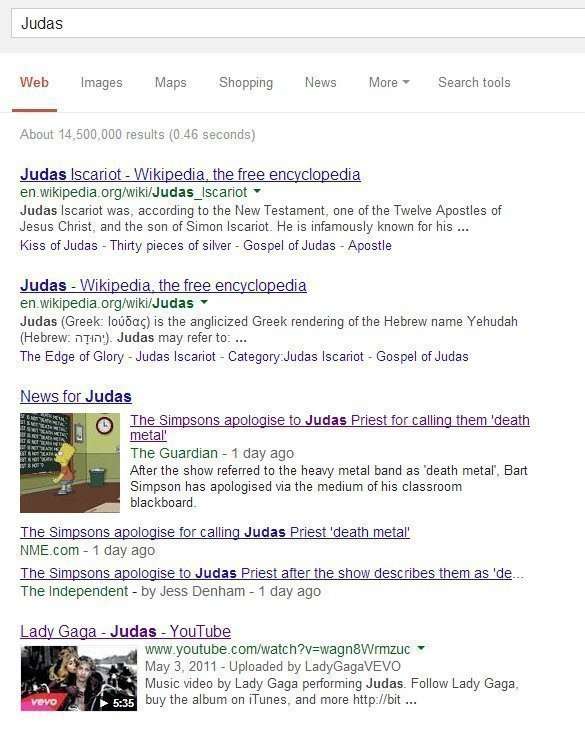
本日、私が作成していた記事の例が、シンプソンズにハイジャックされてしまったようだ。シンプソンズは、Judas Priestをデスメタルバンドと呼んだことを謝罪している。以下の画像は謝罪に関するGuardianの記事に掲載されていたものだ。「Judas」で検索をかけると、この記事は上位に表示される。検索結果のスクリーンショットも掲載しておく:

私は、Googleがキーワードよりも記事のトピックのマッチングを土台にしていると思われる検索結果を探していた — 2013年の大晦日にGoogleに付与された特許によると、トピックのマッチングは、動画やメディアが豊富な検索結果の関連性を改善する可能性があるようだ。そして、この特許が、Judasの検索結果を例として用いていたのだ。
特許に掲載されていた例を紹介する。この例を参考にすると、SEO関係者の大半がマークしていない行動をGoogleが取っていることが分かる — その関係者の中には、Googleが具体的なキーワードよりも、コンセプトを重視するようになることを指摘する者もいれば、また、ハミングバードアップデートにおいて、クエリ内の全てのキーワードにマッチしていない検索結果が返されていることを把握している者もいる。
例えとして、ワード「Judas」を含む検索クエリについて検証していく。このワード「Judas」は、「Born This Way」や「Lady Gaga」等の特定の領域のトピックに関連付けられる可能性がある。「Born This Way」とは、楽曲「Judas」が盛り込まれた人気の高いアルバムのタイトルであり、「Lady Gaga」は、このアルバムを作り、「Judas」のパフォーマンスを行った人物である。
従来のキーワードベースの検索エンジンでは、ワード「Judas」を含む結果のみを返していたはずだが、今回公開されたトピックベースの結果には、ワード「Judas」を含まなくても、関連する結果が組み込まれる。
例えば「Lady Gaga」や「Born This Way」等のワードが、この関連する結果に含まれることもあり得る。
従って、トピックベースの検索結果は、この関連する楽曲のタイトルをユーザーが意識していなくても、同じアルバムや同じアーティストの結果を盛り込むと考えられる。
Googleがトピックベースの検索を実施したため、「Judas」の動画は検索結果に表示されているのだろうか?それとも、ページランクや関連性等に応じてもともと返していたのだろうか?
確実に特定することは出来ないものの、この特許は、詳しく検証し、考察する価値があると言えるだろう。
ランキングのアップデートに関する特許を読み、特許で描かれているメソッドが実際に利用されているかどうかを特定するのは、とても難しい。
今朝、Freebase Google Plus ページに投稿された論文に記されているようなアルゴリズムに対して、Googleがトピックを完全に導入することを阻む技術的な制約が存在しても不思議ではない。
当該の論文「信頼しても、検証は欠かさず: ナレッジベースの創出と取集に対する作品の質を推測」(pdf)(是非目を通してもらいたい)のリンクを提供しようとした際、ある一節を読んでいると、トピックをウェブページのランク付けに利用する取り組みに対して、Googleがどの程度準備が出来ているのか気になった:
このような結果は論文では報告されていないものの、開発段階で、どのコンセプトスペースや専門の描写が最も有益なのか精査を行った。分析の結果は、タクソノミーと述語のコンセプトスペースは、大きなトピックのコンセプトスペースよりも有益だと示唆していた。
トピックのコンセプトスペースは、あまりにも多くのカテゴリーが存在するため、トリプル(主語、述語、目的語)を提供しないユーザーに対しては、専門性を広めると薄くなりすぎてしまうためだ。
この論文は、Googleがユーザーの寄与をFreebaseに統合する仕組みを分かりやすく説明しており、トピックベースの寄与は、その他の寄与ほどは有効ではないと見られている。Freebaseは、Googleのナレッジベースで用いられる情報を供給しているものの、Googleは、Open Information Extraction(公開情報抽出)等、その他のソースを参考にしている可能性もある。
それでは当該の特許を紹介していく:
トピックベースの検索クエリの結果
考案: Jianming He、Kevin D. Chang
付与先: Google Inc.
米国特許番号: 8,620,951
付与日: 2013年12月31日
申請日: 2012年6月1日
概要
開示されるトピックに応じて、クエリに対する結果を返すシステムとメソッド。動画、あるいは、関連するテキストの情報が、通常、その他のタイプのコンテンツと比べて薄い他のメディアのコンテンツを検索する際、特にこのシステムは有効である。
クエリに関連するテキストは、クエリ内の1つ、または、複数のワードを、クエリを前提として領域のトピックの条件付き確率を基に、1つ、または、複数の領域のトピックに振り分けることで、各種の領域のトピックに意味的に関連付けられる。一連の結果は、領域のトピックを前提として結果の条件付き確率を基に特定される。
当然だが、ナレッジベース経由のトピックベースの情報は、この時点でも必要とされているかどうか問う必要がある。
Googleはこの情報を別の場所で得ることが出来るのだろうか?
Open Information Extractionのアプローチは、この手の情報を見つけるメソッドの一つである。Googleは、自動化した情報を得る方法、そして、Freebase等の場所にユーザーが寄与するようなクラウドソース化した手法を利用していると思われる。双方のタイプのソースがお互いを足掛かりにしている確率は極めて高い。
この特許は、トピックの特定を重視する方法は、トピックに関連する確率の計算に左右され、また、複数のステップやタスクに分類される可能性があると指摘している:
まず、領域のトピックは、クエリベースで特定されることがある。次に、この領域のトピックを代表する結果が、示される。このタスクは、過去のクエリに関連する適切なスタッツを分析する、そして、各種の条件付き確率を計算する等の作業によって、達成される。
本特許は、詳細を提供しており、追加の情報が用いられる仕組みにも触れている。
クエリと前提とした領域のトピックの条件付き確率 P(T|Q)は、領域のトピックをクエリに関連付けるために用いられると推測される。領域のトピックを前提とした結果の条件付き確率、P((R|T)は、トピックベースの結果を特定するために用いられると考えられる。この2つの確率、P(T|Q)とP(R|T)は、ここで詳しく説明する様々な手段によって決められる。一部の例では、P(T|Q)とP(R|T)の片方もしくは双方の特定の条件付き確率を決定するための特定の確率が、外部の要素によって決められ、可能な場合、この外部で生成された確率が用いられることもあり得る。
先日、私は、Googleが関連する投稿を特定するために用いているかもしれない方法を「ウェブサイトとのエンティティの関係と関連するエンティティ」の中で説明した。
この特許は、Googleが、同用の方法でトピックをより正しく理解する試みを行っている可能性がある点を指摘している — つまり、「astronomy」(天文学)に対するクエリが、「Hubble images」(ハッブル 画像)を含むトピック(画像を見せびらかす動画を含む)の範囲内として認識される — たとえワード「astromy」がHubbleの画像を掲載するページに表示されていなくても(これも特許で用いられていた例)。
ランク付けに影響を与えるアイテムとして「いいね!/グッド」に触れるGoogleの特許を今まで一度たりとも見たことがない。しかし、トピックベースの特許はこの話題に触れている。ここで言及される「いいね!」が、Facebookのいいね!ではなく、YouTubeの「いいね!(グッド)」である確率が高いが、明確に記されているわけではない(この特許は両者を特に区別しているわけではない)。
「トピックベースの~」特許は、astronomyに直接触れることなく、Hubbleの動画が、検索結果に反映される可能性がある理由を挙げている:
(1) 「astronomy」と「Hubble images」が関連しているコンセンプトとして定着しているため。
(2) 特定の兆候を示すスタッツにより、人気の高さが証明されているため(ビュー数、いいね!の数等)。
「ビュー」は、動画の結果においては確かに有効かもしれないが、この特許の請求範囲のセクションでは、アプローチを動画に制限していない — しかし、特許の記述には、動画等のアイテムに関連するテキストは、限定されている傾向があるため、動画はこのアプローチの対象として適切だと考えられると明記している。
この特許で描かれているプロセスは、今のところまだ実施されていないものの、今後、採用される確率は高い — 実施するかどうかと言うよりも、いつ実施するかと言うレベルである。
今後、実際のクエリにはキーワードは含まれていないものの、トピックにおいて関連性が見られる結果を、私は注意して探していくつもりだ。
この記事は、SEO by the Seaに掲載された「Will Keywords be Replaced by Topics for Some Searches?」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









