![]()

![]()
![]()
毎月30億回以上の検索クエリが入力されるヤフー等の検索エンジンは、調査対象として魅力的であり、検索ログが受け取るデータを分析したくなる。このデータを見れば、異なる時間帯、そして、異なる時期において、人々が何を検索する傾向があるのか特定することが出来るかもしれないからだ。また、検索エンジンを通して、これらの検索を行っているのが男性なのか女性なのか、どこで検索が行われているのか、そして、実際に手にした情報以外にどのような情報が提供されていたのかについて把握することが出来るときもある。
このような分析を行い、データを集めることにより、情報を求める人々のために表示する広告やその他のコンテンツの中で、検索者に何を見せるのかを判断する材料が手に入る可能性があるのだ。

先月ヤフーが取得した特許には、検索エンジンが時間の経過と共にデータを集め、場合によっては10年以上遡り、ヤフーおよび広告を表示するパブリッシャーのページ上でユーザーに見せる広告、そして、ケースバイケースでその他のコンテンツを判断する仕組みが描写されている。以下にこの特許に関する情報を掲載する:
広告の一時的なターゲティング
発明者: アナンド・マーダヴァン氏およびシャム・カプール氏
譲渡先: ヤフー
US 特許 7,672,937
取得日: 2010年3月2日
申請日: 2007年4月11日
要約
広告等のコンテンツの一時的なターゲティング。ターゲティングは時間帯、時期、季節、休日を基に行うことが出来る。
また、以前の検索履歴を活用し、ターゲティングに利用する特定のコンセプトに対する現在の人気を特定することも、そして/または、今後の人気を予測することも可能。
ヤフーは検索エンジンで検索が行われるとスポンサー付きの広告を検索結果と共に表示しており、さらに、パブリッシャー・ネットワークを通してパブリッシャーのウェブサイトでも広告を提供している。広告は検索した際の検索クエリ、もしくは、パブリッシャーのページのコンテンツを基に掲載される傾向がある。しかし、検索クエリもしくはコンテンツとマッチする広告がない場合はどうなるのだろうか?
これらのページ上に広告を掲載する際に、異なる時間帯や時期における興味に関する情報は役に立つのだろうか?
もしヤフーが時間を割いて人々が検索する際に用いるクエリの用語を分析し、これらの検索におけるパターンを見つけ出すことが出来るなら、夜には不眠に関する製品や記事を探す傾向、朝には株価に関する情報を探す傾向が判明するのではないだろうか。また、検索エンジンはハロウィーンが間近に迫るとコスチュームやキャンディーに関するクエリが用いられる点を特定するだろう。
もしヤフーがリアルタイム、もしくはほぼリアルタイムでクエリを分析することが出来るとするなら、数時間のうちに特定のクエリの人気が急激に上昇すれば気付くはずである。この特許によると、検索エンジンは最大で10年前に遡り、休日や季節に関連するトレンドを記録することが可能なようだ。
時間、日付、もしくは季節を基に広告やそのほかのコンテンツをターゲットに選ぶことで、そして、特定の期間の過去の閲覧や検索の履歴を分析することで、ターゲットを絞る際に最も人気/関連性が高いであろうトピックやアイテムを推測することが出来る。
この特許によると、ユーザーの行動に関連する広範な情報を検索ログのデータベースで探し、表示する広告やその他のコンテンツを決める際に役立つコンセプトやトピックを特定するようだ。検索エンジンはこのプロセスを広告のターゲティング以外の目的でも利用する可能性があるが、特許には主に広告の選定に利用すると記載されている。
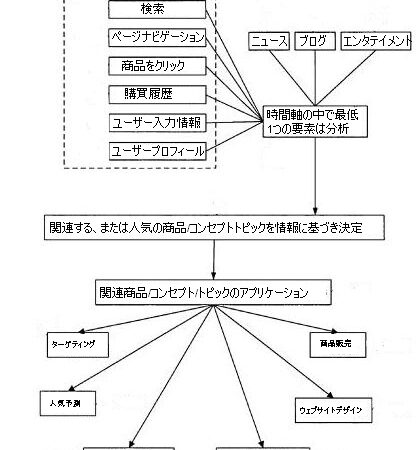
このターゲットメソッドで分析される可能性がある、ユーザーのデータのタイプを幾つか挙げていこう:
検索 – 検索クエリは時間が経つと、人気が高まる可能性のあるトピックを示唆するパターンを示す。
ページの閲覧 – ブラウザーが表示もしくはスクロールオーバーするページおよびページ上のアイテム。
製品のクリック – クリックされた広告、そして、閲覧された製品ページ。
購入履歴 – 製品やサービスの実際の購入履歴。
ユーザーの入力 – ウェブサイトに入力する情報の類。
ユーザーのプロフィール – オンラインプロフィールを作るために入力する情報。性別、誕生日、場所、趣味など。
また、オンライン上のアクティビティに関するその他の情報源も考慮されているようだ:
トピックやコンテンツの人気を特定する入力の種類として、追加的な情報が利用される可能性もある。例えば、ニュース、ブログ、娯楽サイト等は特定のコンセプトの人気を予測する上で役に立つデータを得ることが出来る可能性がある。
例えば、履歴データが、ニュースの中でハリケーンの話題が上がるたびにユーザーが保険のコンテンツを閲覧していることを示唆している場合、ニュースでハリケーンが出てくると保険が人気の高いコンセプトになることを物語っている。
同様に、ブログや、映画、テレビ番組等の娯楽サイト、もしくはスポーツ関連のサイトもまた、トレンドのコンセプトを特定するためのデータを加える。そして、最も話題に上がったトピックを特定するために、娯楽に関するニュースやブログはモニタリングされる。
ヤフーが1ヵ月で30億回ものクエリを受けている点を最初に述べたが、このデータはタパス・カヌンゴ氏のホームページに掲載されているものだ。同氏は、同氏が取り組んだヤフーのスニペットの生成プロセスによって、1ヵ月で約30億ものスニペットが表示されるようになったと説明している。
これほど多くの検索を分析すれば、人々がある時点で興味を持った事柄に関する情報を豊富に得ることが出来るだろう。常識でも、晩秋から冬にかけて雪かき用のシャベルに対する関心が高まり、晩春から夏にかけて水着に関する関心が高まることは推測できる。
しかし、その他のトピックや関心を含むパターンを明らかにする可能性を秘める、数時間もしくは数十年間に及ぶ大量のデータを手に入れることで、検索者の興味を掻き立てるアイテムに関する鋭い見解を得ることが出来るかもしれない。この情報を用いて、広告をターゲティングすることで、ページ上のコンテンツ、もしくは検索で使われたクエリに表示する妥当な広告がない場合に表示する広告がクリックされる確率は高くなるのではないだろうか。
この情報を他の用途に利用することが出来ると私は思うが、このエントリで取り上げた特許には、その他の可能性については深く語られていない。
この記事は、SEO by the Seaに掲載された「A Time and Season for Search: How Data Mining Can Influence Search Advertising」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









