![]()

![]()

グーグルは、4月に3000万ドルと少しを投入し、Waviiと言う会社を買収した。当時、ウェブのニュースをまとめるSummlyを買収したヤフー!に対抗して、グーグルはWaviiを買収したと言う噂が出回っていた。

Waviiもまた、ウェブ上でニュースを取得 & まとめるアプリである。事実、Waviiがデビューした際、キーワードよりもトピックに的を絞った、パーソナライズされたニュースアグリゲータとして注目を浴びていた。しかし、先程紹介したテッククランチの記事を読む限り、このアプリは、グーグルに買収されたことを受けてサービスを閉鎖しており、ニュースアグリゲーションサービスを提供するのではなく、グーグルニュース、ナレッジベース、そして、グーグルグラスの原動力として陰で支えているようだ。
それでは、Waviiは、どのようなテクノロジーを利用しているのだろうか?
オーレン・エチオーニ氏が2011年にNatureに寄稿した記事で、グーグル、ビング、ウルフハラムアルファ、そして、検索の未来の限界(pdf)を指摘した際、Waviiが単なるアグリゲータではないと示唆していた。検索の未来とは何を意味しているのだろうか?次の動画で概要の説明が行われている:
動画内のグーグルとグーグルのナレッジベースの比較、そして、次の発言には刺激を受けた:
次世代の検索エンジンを作ることが目標だ。
グーグルが買収した際にWaviiが保有していた特許を調べた結果、ウェブからの公開情報の抽出(pdf)がWaviiに付与されていたことが分かった。
この特許、そして、申請中の補足の特許を以下に挙げる:
ウェブからの公開情報の抽出(付与された特許)
ウェブからの公開情報の抽出(続きの特許。新たに項目が加えられている)
発明: マイケル J. カファレラ、マイケル・バンコ、オーレン・エチオーニ
付与先: ワシントン大学 センター・フォー・コマーシャリゼーション
米国特許番号: 7,877,343
付与日: 2011年1月25日
概要
公開情報抽出を実装するため、新たな抽出のパラダイムを策定した。このシステムでは、単一のデータドリブンのパスをコーパスの上に作り、人間によるインプットを必要とせずに、大量の関連する一連のタプルを抽出する。訓練データを使って、セルフスーパーバイズド・ラーナーは、パーサーと経験則を用いて、基準を判断する。この基準は、コーパスから抽出された候補のタプルの信頼性を評価するため、抽出識別子(あるいはその他のランキングモデル)によって用いられる。この時、経験則がコーパスに対して適用される。
識別子は、信頼できる可能性が十分に高いタプルを維持する。また、冗長ベースの評価システムが、維持するタプルに対して、当該のタプルが、タプルを構成する複数のオブジェクトの間の関係である可能性を示唆する確率を割り当てる。維持されたプルは、情報に対して問い合せを行うことが可能な抽出グラフを形成する。
ここでは、特許を詳しく分析するのではなく、この公開情報抽出システムの仕組みを深く理解することが可能なリソースを幾つか提供する。
一つ目のリソースは動画である: 
ウェブスケールでの公開情報抽出
(長い動画だが、視聴する価値はある)
以下の文書およびページにも詳細な情報が掲載されている:
教訓
Waviiは、グーグルが買収する前に提供していたニュースアグリゲータアプリをグーグルにもたらすわけではない。グーグルの検索エンジンに導入される公開情報抽出のアプローチは、ウェブ上のテキストを読むことを目的としており、所定のテンプレートや管理を必要としない。
抽出のアプローチは、名詞、そして、名詞と名詞の関係を作り出す動詞を用いて、名詞の関係を特定し、関係の質を評価する。そして、「識別子」がそれぞれの関係の信頼性を識別し、信頼できる関係のみを維持する。
関係内の用語(“タプル”と考えられる)は、逆索引に保存され、クエリに対して用いられる。以下に、ウェブのクロール中に特定された、このインデックスの一部となる可能性がある関係の例を挙げていく:
(
この限られた量のデータを用いた公開情報抽出の一例が、Revminerであり、シアトルのレストランに関する情報を検索するために用いることが出来る。
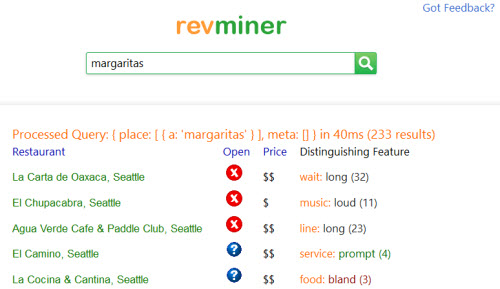
Waviiと共にグーグルが買収したシステムが、コンテキストに基づき推測されるクエリを用いて、グーグルのナレッジベースとグーグルナウを改善するポテンシャルは高い。公開情報抽出は、未完成だが、未来の検索において重要な役割を果たす可能性があるのではないだろうか。
この記事は、SEO by the Seaに掲載された「With Wavii, Did Google Acquire the Future of Web Search?」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










