![]()

![]()

Moderator:Danny Sullivan(Founding Editor, Search Engine Land, @dannysullivan)
Speakers:Marcus Tober(Founder/CTO, Searchmetrics Inc., @marcustober)

RankBrainについて、Googleはそこまで詳細な情報を与えてくれていない。しかし、我々が知っておくべきことであることは間違いない。(ダニー氏)
イントロダクション
このセッションでは、GoogleのRankBrainとは何なのか、どのような仕組みなのか、何を意味するのか、についてお話しする。
マシンラーニング(機械学習)? AI(Artificial Intelligence:人工知能)?
マシンラーニングはAIとイコールではない。マシンラーニングは、時間をかけて改良していくアルゴリズムである。AIは、人間と同様の知能である。また、ディープラーニングは、マシンラーニングとAIのギャップを埋める目的で、より複雑な問題を処理することができる。
マシンラーニングの技術を用いた例
スパムメールのフィルタリング、Facebookの写真認識、iTunesなどの音楽や動画のレコメンデーション機能、チェスなどのボードゲーム(対戦ロボット)、などが身近な例だろう。
囲碁:マシンラーニングの限界
囲碁は2,500年の歴史があり、世界中に4,000万人のプレーヤーがいる。マシンラーニングでは打ち破れないと考えられていた(AlphaGoまでは)。囲碁は非常に難しいゲームだ。駒の移動パターンは、チェスの場合10の50乗だが、囲碁の場合は10の171乗にもなる。
ちなみに、Googleという名前の由来は”Googol”であり、10の100乗を意味する単語だ。
ディープラーニングとAlphaGo
今までの伝統的なAIの手法は、移動可能な全てのポジションを分析しようとしていたが、囲碁の場合は数が膨大なため、うまくいかなかった。AlphaGoは12の異なるネットワークの層をまたぐ、深いニューラルネットワークを使用している。1つのニューラルネットワークは次に動くべき手を選び、別のニューラルネットワークはゲームの勝者を予測している。このように、Googleは常に、問題を解決しようとしている。これはRankBrainにも当てはまる。
RankBrainを理解しよう
ジェフリー・ヒントン氏(トロント大学の教授であり、Googleでも活躍)の功績の賜物でもあるプロジェクトがある。これを簡単に説明してみよう。まずは、”thought vectors”の話だ。何もない空間を想像してほしい。そして、この世の全ての言葉がその空間に配置される。それぞれの言葉にはポジションがあり、別の言葉との近接(距離感、近さ)を持つ、というイメージだ(それぞれの言葉と言葉の距離=関係性を把握する)。Googleは検索クエリをマッピングし、それぞれのクエリの距離を測ることができる。

ある言葉とある言葉の距離が近いことをGoogleは理解しており、それぞれの関連性を見出す。そして、良い検索結果は距離感に基づいている。RankBrainは、”カリフォルニアの天気はどんな感じになるかな?”という話し言葉のようなクエリを、”天気予報 カリフォルニア”と解釈することができ、それに近しい検索結果を出している。クエリ内の言葉を、その言葉と近しい距離の別の言葉に置き換え、それを元に検索結果を提供することで、良質な検索結果を得られるのだ。
Searchmetricsによる仮説
伝統的なランキング要素は全く意味が無くなっている、という仮説を立てた。現在、RankBrainはすべてのクエリに使われてはいないが、今後全てのクエリに使用されればどうなるだろうか?あるクエリに対してRankBrainが使われた場合、3番目に重要なシグナルとなる。下記に、我々の仮説をまとめる。
調査内容
下記に、今回調査する上での基準をまとめる。
いわゆる、伝統的なランキング要素では説明がつかない例がある。例えば、”cash advance fresno ca”というクエリでは、5位に表示されているサイトは12位に表示されているサイトよりも、バックリンク数や内部リンク数で圧倒的に低い数字が出ている。

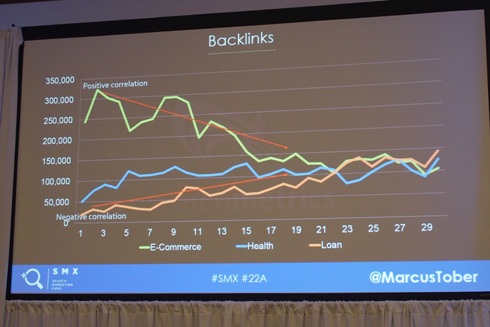
既存の要素1:バックリンク数
”Eコマース”の相関関係はポジティブ。つまり、リンクが多ければ順位が良いという状況。”ローン”の場合はネガティブ。少ないバックリンク数でも上位表示されている。
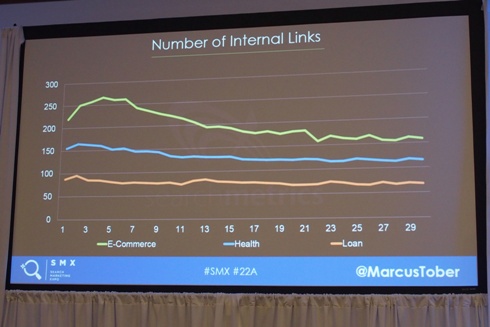
既存の要素2:内部リンク数
全体的に”Eコマース”で内部リンクが多いのは、多数の商品ページがあるなど、納得できる理由はある。
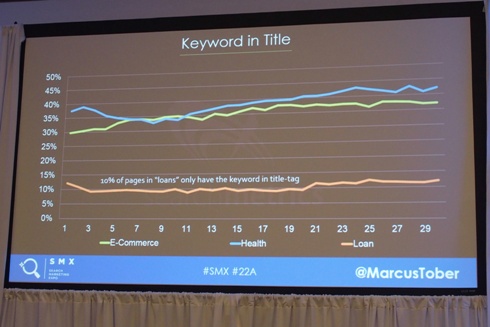
既存の要素3:タイトル内のキーワード
”ローン”では、タイトルタグ内にキーワードが入っているページは10%ほどだ。
既存の要素4:単語数
”Eコマース”と”健康”では単語数が多いほうが上位表示されている。つまり、コンテンツが多いほど有利ということだ。
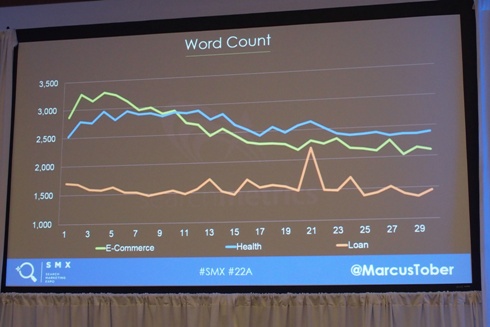
上記4つの例の中で、今までの理論が通用しない検索結果があった。例えば、バックリンク数が少ないページや、単語数が少ないページが上位表示されていることがあった。なぜ、伝統的な要素がランキング要素になっていない例があるのだろうか?
関連性の要素
我々は、RankBrainをエミュレートし、関連性のスコアをつけた。このスコアは、クエリに対する検索結果との関連性に基づいている。我々は、この関連性を測定するため、(関連性についての)25種類のランキング要素を使用した。この要素はキーワードによって異なるため、具体的に何かを説明することは、ここではできない。
Eコマースの例1
“security camera system(セキュリティ カメラ システム)”というクエリの例。1ページ表示のうち、9つのサイトにカート機能がついていた。9位に表示されていたサイトのみがついていなかったのだが、なぜ、このサイトは1ページ目に表示されているのか?このサイトの関連性のスコアは、上位30位の内、最も高いスコアであった。

Eコマースの例2
“best bluetooth headphones(ベスト ブルートゥース ヘッドフォン)”というクエリの例を見てみよう。2位に表示されているサイトの内部リンク数は、26位のサイトよりもかなり少ない。しかし、2位に表示されているサイトの関連性のスコアは、上位30位の中で最も高かった。

健康の例
“natural detox(ナチュラル デドックス)”というクエリの例。5位表示のサイトを見ると、単語数、内部リンク数、インタラクティブの要素、などが全て26位に表示されているサイトよりも低い。

関連性スコアのまとめ
関連性スコアの高いサイトには、以下の特徴がある。
調査結果のまとめ
この調査によって得られた結果を以下にまとめる。
SEOへの影響
SEOが重要であることに変わりはないが、変化している。新しく導入されたRankBrainは、全てのクエリで使用されているわけではない。短い、人気のあるクエリの、すでに定番となっているような検索結果に対しては、RankBrainによるフィルタリングはないだろう。
RankBrainは関連性を見ており、関連性は高順位を獲得するうえで必須の要素だ。つまり、ユーザーのインテントとあなたのコンテンツを合致させることが、SEOにおいて重要なことであると言えるだろう。
検索の未来
強力なデータ分析から得られた改良の積み重ねが必要であり、マシンラーニングとディープラーニングは、複雑なデータから意味を見出す。データドリブンなアプローチこそが求められており、これは、コンテンツにもあてはまる。
この考えは、RankBrainとSearchmetricsで共通した考え方である。
Eric Enge(CEO, Stone Temple Consulting, @stonetemple)

2013年に脳の外科手術を受けた。しかし、これが今回私がRankBrainについてお話しする理由と関係があるわけではない。
RankBrainとは何か?
2015年10月に、ブルームバーグの記事によって明らかになった。その記事では、”RankBrainは言語やクエリを、人の直感や推測する方法と似た手法で、解釈する”と記載されている。つまり、”Googleは言語理解を深めている”、ということだ。
言語分析のコンセプト
RankBrainだけに限った話ではない、基本的なコンセプトをお話しする。まずは、ストップワード(Stop Words)だ。これは、”a”や”the”や”such”など、言語処理をする前にフィルタリングされる(不要な)単語だ。しかし、ストップワードを除外してはいけない場合もある。
ストップワードが必要な例
例えば”The Office” の”The” は重要。テレビドラマの名前の場合もあるし、会社という意味もある。また、”coach”という単語も、ブランドを意味する場合もあるだろう。同一のセンテンス内に、”バッグ”が含まれていたり、”Coach”と大文字で表記されていた場合、監督という意味の”coach”と違うことを人間は理解できる。
RankBrainの働き
上記の例の人間が理解できる部分を、アルゴリズムで可能にしたものがRankBrainだ。RankBrainは言語内の関連性を理解し、該当の単語の意味を解釈する。実際、ゲイリー氏はRankBrainを以下のように説明している。
“RankBrainは非常に高次元の空間においてテキストの文字列を表現することを可能とし、それらが互いにどのように関連しているのかを見ている。”
RankBrainと関連性の理解
RankBrainはある言葉のパターンを分析する。その言葉が使われているフレーズ、同一センテンス・パラグラフ・ページで使われている言葉、コンテキストやコンセプトなどだ。こうした分析の結果、”The”を典型的なストップワードではあるが、意味を決定する場合がある、という理解をし、”The Office”というクエリの意味を解釈する。
具体例1(単語の置き換え)
Googleが引用した例を用いて説明しよう。ブルームバーグの記事には、以下の文章が例に出されていた。この文章内の、それぞれの単語の意味を置き換えている。

【SEO Japanによる補足】
上記を直訳すれば、”食物連鎖の最も高いレベルにいる消費者のラベルは何?”になります。そして、文章内のそれぞれの単語を以下のように置き換えています。
・label(ラベル)→ Name(名前)
・consumer(消費者)→ “消費者”のままですが、購入する(顧客)ではなく、捕食する存在としての“消費者”と理解します。
・highest level(最も高いレベル) → TOP(頂点)
・a → the (”the” にすることで、”食品チェーン店”ではなく、”食物連鎖”という意味を強めます。)
こうした置き換えを行った結果、”食物連鎖の頂点にいる消費者の名前は何?”というクエリと解釈し、それに関連した検索結果を出すことになります。
具体例2(withoutの扱い)
“Without”は“The”と同じように、Googleによってしばしば無視されてきた単語である。否定の意味を持つが、ページの意味を決定するうえで重要な場合もある。次の文章を例にしてみよう。

“攻略本無しでスーパーマリオの100%のスコアを叩き出せるか?”というクエリになる。”without”の部分(”攻略本無しで”)を無視していれば、このクエリに対する正確な検索結果を出すことはできなかっただろう。実際、ゲイリー氏は”without”の扱いについて、以下のように説明している。
“かつて、クエリ内のwithoutの部分は無視されていた。RankBrainはwithoutの意味を把握するために素晴らしい仕事をしており、正確な検索結果を提供できている。”
我々が行った調査
GoogleとBingのサジェストから、50万のクエリを抽出し、データベースを構築した。そして、2015年の6月・7月と2016年1月の検索結果を比較し、正確に理解できていなかったクエリ(正しい検索結果を返していないクエリ)を探した。数を以下にまとめる。
また、改善の内容を下記にまとめる。
改善例1
“why are pdf so weak(なぜpdfは脆弱なのか?)”というクエリの例。2015年7月の検索結果はPDFファイルが検索結果の上位を占めていたが、2016年1月の検索結果ではPDFのセキュリティを解説したページが1位になっている。


改善例2
“Where is Celtics Bench?(セルティックのベンチの場所は?)”というクエリの例。”Where is”の解釈が改良されており、”セルティックファンにとってベストな席”というタイトルのページが1位になっている。

改善例3
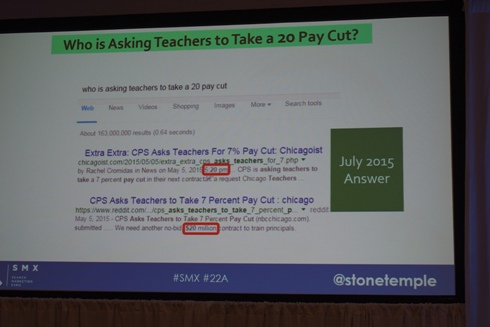
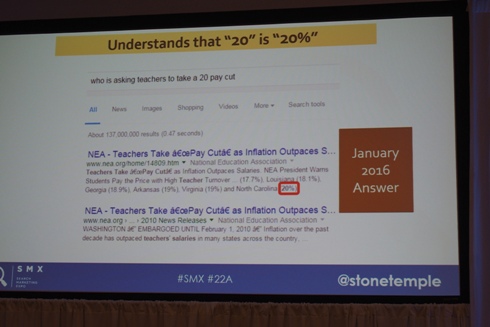
“who is asking teachers to take a 20 pay cut(教師に20の減給を求めたのは誰?)”というクエリの例。ここで、”20”が”20%”を意味していることを理解するようになっている。
改善のまとめ
フレーズや単語の解釈の改善が見られた。また、”What is”、”Where is”、”Not”などといった特定の単語やフレーズの理解が進んでいた。また、珍しい名前、スペルミス、誤解がある(別の意味に解釈できる)単語、などの理解も進んでいるようだ。
SEOにおける影響とまとめ
今のところ直接的な影響はないと考えている。しかし、覚えておくべきことをまとめてみよう。

Googleによると、RankBrainは複雑なクエリの理解で使われている。
長いクエリを短いクエリに置き換え、同等の検索結果を提供する。しかし、このセッションでも話されたように、他の要素ともなっている。
ところで、我々は何をすれば良いのだっけ?
パンダやペンギンの時は、対応策が明らかだった。しかし、ハミングバードは完全にアルゴリズムを変えた。RankBrainもそのようなイメージ。(マーカス氏)
構造化データとRankBrain
構造化データは検索結果での表示を変える、という意味合いが強い。レビューとか、栄養素とか。ナレッジグラフでも、Googleは使用している。個人的には使うことをおすすめする。(マーカス氏)
構造化データは適切に設置されれば、強力なシグナルになる。(エリック氏)
RankBrainをスパムやブラックハットに使う方法は?(笑)
あとでこっそり僕のとこに来てくれ(笑)(エリック氏)
SEOは新しいことが出る度に、それを利用しようとする。コンテンツが話題になった時は、高品質なコンテンツのテンプレートをくれ、などとよく言われた。こういうのが問題だと思う。(マーカス氏)
他の言語ではどうだろうか?
アムステルダムで同じ調査をしたけど、Google.comよりも3年位遅れている印象。スパム的な感じが多かった。言語が複雑だからだろう。(マーカス氏)
RankBrainは、クエリの精製とシグナルの2つの話しが平行している。それが状況を難しくしている。AIがどうやってクオリティを決めるのか?複数の写真から猫を認識することはできる。だが、ベストな猫をどう決めるのか?(ダニー氏)
囲碁の場合、パターンを全て予測し、ベストな手を決定している。(マーカス氏)
それはルールがあるからでは?(ダニー氏)
オイルフィルターの例。オイルフィルターで検索した後、多くの場合で次のクエリが決まっている。そういったユーザー行動の影響もあるのでは?(エリック氏)
*色々と議論は尽きないという感じでした。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










