![]()

![]()
チャプター 4を終える頃には、強固なウェブサイトが出来あがっているはずである。しかし、SEOは、スピード、インデクセーション、そして、メタデータだけではない。
チャプター 5では、ImportXMLを用いたオフサイトSEOから説明していく。
目次
ImportXMLとは、html、xml、csv等のファイルの種類から、xpathを使って情報を引き出す手段である。
グーグルドキュメントのスプレッドシートに直接インポートすることが出来るため、外部サイトの情報を取得し、調達する上で大いに役立つ。また、高度な検索を実施して、他の方法では取得することが難しい情報を得ることも可能である。
ImportXMLを使った例を紹介していく。
基本的なシンタックス
ImportXMLはエクセルやグーグルドキュメントの数式と同じであり – 割とシンプルなシンタックスを利用する:
=importXML(URL, Query)
URL = 取得するURL
Query = URLで実行するxpathクエリ
基礎の例 – クイックスプラウトのH1タグを取得する
新しいグーグルドキュメントのスプレッドシートを作成する。

URLを設定する。

基本のxpathの関数を作成して、ページのH1を取得する(スクリーミングフロッグ、または、サイトのクロールを介して同じ作業を行うことが出来るが、分かりやすい例を紹介するため、この方法に拘っていく)。
importxml関数をセルB2に加える。

URLが存在するA2を参照している点に注目してもらいたい。
クエリは引用符で囲まれる。
次にxpathは返されるファイルの部分を特定する。//h1は、ページのh1を含む全てのコンテンツを返す(これは“//”のパーツによる命令であり – どれだけレベルが深くても、あるいは、どれだけネストされていても、全てのh1“path”を求めることが出来る)。
次のアイテムが返される:

これで投稿のH1をグーグルドキュメントに引き出すことに成功した。次に、グーグルドキュメントのimportxmlにおいて、有意義な例を幾つか挙げていく。
次にクオラを使って、ツイッターのURLにおいて影響力の強い、あるいは、権力を持つ可能性のあるユーザーを調達する方法を伝授する。
以下に最終的な結果を表示する。この結果を目指して、これから作業を進めることになる:
ステップ 1 – グループまたはトピックを探す
この例ではブログのトピックを取り上げる – https://www.quora.com/Blogging/followers

ステップ 2 – カラムAにクオラのURLを入力する

カラムBで実行されている関数の中で、このセルを参照する。
ステップ 3 – importxmlの関数を作って、ユーザー名を取得する

関数を以下に挙げる:
=importxml(A2, “//h2/a/@href”)
コードを理解し、作りやすいように、関数を分解していく。
ご覧のように、この関数はブログのトピックの上位20名のユーザーをリストアップする。

ステップ 4 – 完全なURLを作成する
既にお気づきかもしれないが、クオラは相対URLを使ってリンクを張るため、絶対URLにコンバートする必要がある。
シンプルにconcatenate関数を利用する:

因みにconcatenate関数を念のために掲載しておく:
=CONCATENATE(“https://quora.com”,B2)
このコードも分解していく。
この作業を終えたら、今度は数式を掴み、カラムの残りに引き下げていく:

ステップ 5 – ツイッターのURLを取得する
最後の仕上げとして、ツイッターのURLを取得する。

以下に関数を掲載する。長いので区切って一つずつ説明していく:
=ImportXML(C2,”//div[contains(@class,’profile_action_links_section’)]//a[contains(@href,’twitter.com’)]/@href”)
HTML内のクオラのコードのスクリーンショット:

忘れずに数式をつかみ、カラムの残り全てに引き下げよう。

これで、20名のツイッターのユーザーを1度に取得することが出来るようになった。これは技術的なガイド(How To)であり、このリストをどのように使うかに関しては、皆さんの判断に任せる。きっと様々な用途が浮かび上がるはずだ 🙂


 スプレッドシートがUbersuggestの答えで埋まる:
スプレッドシートがUbersuggestの答えで埋まる:

一度に100(または100以上)の候補のサイトを手っ取り早く探し出す方法をこれから紹介する。高額なリンク発見ツールを使って、この取り組みを行うことも出来るが、予算が少ないなら、または、ツールの数を減らしたいなら、この方法は大いに役に立つだろう。しかも、とても簡単であり、また、楽しいと言うメリットもある。
この方法は、コンテンツの一部ではないリスト – つまりコードでHTMLを探している際に役に立つ。この例では、‘rel=author’タグを探していく – この作業には2つの意図がある。まず、ウェブサイトのオーナーは、わざわざ時間を割いてこのタグを設定するくらいなら、マーケティングの観点から見て、出来るだけ上の方に陣取ろうとするはずである。次に、ウェブサイトのオーナー(または助っ人)はある程度の技術的なスキルを持っていると考えられ – 協力を容易に要請することが出来る可能性がある。
これから挙げていくステップに従ってもらいたい:
1. グーグル検索を幾つか考える。
2. 結果を取得する。
3. スクリーミングフロッグを使って、リストの特定のコードを探す。
ステップ 1. グーグル検索
リンクを獲得することが出来る可能性のあるサイトのリストを手に入れたい。ここでは、食べ物をテーマにブログを運営しており、ゲスト投稿を行うため、他のブログを探していると仮定する。次のような検索を実行することが考えられる:
food inurl:blog intitle:submit post
food inurl:blog intitle:contribute post
あるいは、キーワードを使ってさらに具体的な検索を行う手もある:
gourmet food inurl:blog intitle:submit post
eclectic desserts inurl:blog intitle:submit post
良質な検索を実施すると、結果内に複数のサイトの候補が表示されるはずである – 多過ぎても良くない。例えば:

手始めに上のクエリから取り掛かることを薦める。
2. グーグルの結果からURLを取得する
グーグルの結果をテキストドキュメントにまとめ、スクリーミングフロッグを実行する準備を整える必要がある。
1. 準備段階として、1つのページにつき100点の結果を返すようにグーグルを設定する。
検索の設定にアクセスする。
ページあたりの表示件数を100に設定する

グーグルに戻り、再び検索結果を表示させる。
次にSERP Redux ブックマークレットを使う – リンクをクリックする。

URLのリストをクリップボードにコピーする。

テキストエディタに貼り付ける。

.txtファイルとして保存する。
3. スクリーミングフロッグを介してURLを絞り込む
1. スクリーミングフロッグをリストモードに設定する。

2. テキストファイルを選び、開く。


3. Custom設定にアクセスする。

4. 絞り込むHTMLを入力する。

この作業を実施する方法が鍵を握っている。
次の4つのリストを作成する:
5. カスタムの結果を見る。
‘custom’タブをクリックする – すると、フィルター1-4を選択することが出来るようになる。

このケースでは、リストにはrel=authorを持つブログは1つしか存在しなかった。それで問題はない。と言うよりも、むしろその方が良い。全ての結果を確認して、オーサーシップを持つ結果を探す作業を想像してもらいたい。これで、ターゲットが絞られた候補のサイトを1つ手に入れたことになる – このプロセスを実施して、さらに多くの候補のサイトを見つけることが可能だ。
このセクションでは、有料ツールの利用方法を紹介する。無料バージョンも用意されているものの、全ての機能を利用することが出来るわけではない。ただし、このセクションで取り上げている作業に関しては、恐らく、無料バージョンでも足りるだろう。因みに、私はこのツールのアフィリエイトに参加しているわけではない。
作業を始める前に、 – https://www.whitespark.ca/local-citation-finder/にアクセスし、無料版または有料版のアカウントの登録を行う。
パート 1 – 検索(プロジェクトなし)
一つ目のタブをクリックし、個人情報をフィールドに入力していく。

数分間待つ:

レポートの準備が整うと、eメールの通知が送られてくる:

すると次のようなレポートを見ることが出来るようになる。「compare citations for these businesses」をクリックする。

その後、csvとしてレポートをエクスポートする。

エクセルファイルとして開き、保存することが出来るようになる – これから、どのサイトが最もサイテーションを得ているのかを容易に判断することが出来るように、少しカスタマイズを加えていく。
次のエクセルの数式を利用する:
=COUNTIF(A2:A111,”*Y*”)
このように表示される(カラムBにカーソルを合わせている場合):

全てのアイテムをカウントするため、横方向にドラッグする:

もちろん、オートフィルタをかけ、YまたはNだけを見ることも出来る:

パート 2
パート 1は、一般的な候補を探す上では役に立つが、レポートに含まれていない場合はどうすればいいのだろうか?「search by phone number」機能を利用すればよい。
自分の電話番号、または、会社の名称(電話番号が最も有効であり、肩書きによる検索は難しい)を利用することが出来る。
情報を入力していく。このレポートをプロジェクトに加える:

忘れずにプロジェクトを作成してもらいたい。

生成されるレポートには、キーワードにとらわれないサイテーションのソースが全てリストアップされる。

小さな+をクリックすると、サイテーション(通常は電話番号を意味する)付きのページを見ることが出来る。

データのエクスポートに関しては、複数の選択肢が用意されている:

Re-run and append – 同じレポートを再び実施し、以前見つからなかった新しい結果を加える。
Export CSV – データをエクスポートする。ウェブサイトの名前のみが表示され、URLは表示されない。
Export CSV w/URLs – フルレポートでURL(+をクリックすると表示される)が表示された状態でエクスポートする。
データ取得のこのセクションでは、Citation Labs Contact Finderを利用する – https://citationlabs.com/tools/ – 始める前にアカウントを作成する必要がある。
候補のURLのリストを持っている場合、このツールはとても役に立つ – 接触する上で必要なeメールアドレスを速やかに手に入れることが出来る。
パート 1 – URLを集める
(このガイドを参考にして)候補のURLリストを持っているか、あるいは、リストを要領よく手に入れられる方法を心得ていると仮定して、話を進めていく。
この例では、取得したグーグルのURLのリストを利用する – 私が食べ物をテーマに取り上げるブロガーであり、レシピを投稿する機会を狙っていると仮定する。その場合、次のような検索をかけることが考えられる:
recipe inurl:submit

検索を実行したら、Contact Finderにアクセスする。
次にフォームに記入する。

通常のエクスプレッション(regex)を使って、結果を調整することが出来る。例えば、このエクスプレッションは:
^(Contact|About|Email|Submit)
contact、about、email、または、submitで始まる結果を求める。
私ならアンカーテキストをワード数で限定しないようにする。
Contactsタブをクリックして、結果を取得する(処理に数分間要することもある)。

ご覧のように、幾つかの種類の結果が存在する:
次に、個別のレポートまたは全てのレポートをCSVにダウンロードすることが出来る。

ご覧のように、100本のURLの中から、次のアイテムを獲得している。
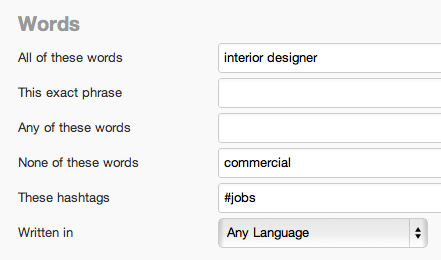
別のツールで検索を設定する前に、まずはフォローするべき高度な検索のリストを策定する必要がある。
インテリアの装飾をテーマに取り上げていると仮定する – その場合、出来るだけ多くのバリエーションを持たせるべきである – キーワードリサーチと基本的にほとんど変わりはない。
こののワードが中心的なワードになる。次に意図を判断するためのワードのリストを手に入れる:
特定の場所をターゲットにする場合:
ブランドも忘れずに(私の場合):
このようなキーワード、そして、検索の組み合わせを行うと、キーワードの言及を全て拾い集めることが出来る。具体的なユーザーをモニタリングする方法は後ほど紹介する。
次のURLで自分で検索を作成し、テストすることが可能だ: https://twitter.com/#!/search-advanced

過去12-24時間以内の複数の結果を入手することを目標にしよう。

IFTTTのレシピを作成する
次に、モニタリングしたい検索が見つかったら、IFTTTのレシピを作り、実行させることが出来る。IFTTTの長所は、様々なプラットフォーム全体で通知を受けることが出来る点である。それでは、アラートが動作する際にeメールまたはテキストメッセージを送信する設定を紹介していく。
注記: 結果の頻度が少ない場合、とりわけ有効である。
アカウントを作成し(無料)、新しいレシピを作成する。

「trigger」としてツイッターを利用する。

「New tweet from search」を選択する。

検索のフィールドに記入する – 単純な検索なら、プレーンテキストを利用することも可能だが、高度なオペレータを利用する必要があるケースが考えられる。

「Action」チャンネルとして、eメールまたはGメールを選択する。

フィールドに記入し、必要に応じてカスタマイズする。

テキストメッセージを受信したい場合:
「Action」としてSMSを選択する。

フィールドを設定する。

後はeメールが届くのを待つだけだ。

おまけ: eメールのフィルターを設定する
情報収集の取り組みGメールのフィルタリング機能を使って、さらにレベルアップさせることが出来る。フィルターを作成し、フォルダーに全てのアラートを送信する:


高度なツイッター検索のシンタックス
幸いにも、ツイッターの高度な検索を生成するツールを利用すると、代わりに検索を考えてもらえる:
次のURLにアクセスし: https://twitter.com/#!/search-advanced 検索を実行する – 結果にはオペレータ付きの検索シンタックスが含まれるはずだ:
![]()
ツイッターでインフルエンサーの声に耳を傾ける
インテリアデザインの分野の例を再び取り上げる。今回は、ブログを運営しているインテリアデザイナーとのつながりを増やしたいと仮定する。いつ、助けを必要としているのかを把握しておきたいところだ。
まず – followerwonk等のツールを使って、情報を集めることが出来るユーザーを探し出す: https://followerwonk.com

次に、手を貸すことが出来る点を誰かがメンションすることを考慮し、高度な検索を作成する。コンピュータのエキスパートなら、次のような検索を利用することが出来るのではないだろうか:

ターゲットの人物は、1年に1度しかツイートを投稿していないかもしれないが、大物とのつながりを作ろうとしているなら、IFTTTのレシピを作成し、テキストメッセージを介して、当該の人物が助けを必要としている時に、通知してもらう価値はあるはずだ。
ここでも、ツイッターの検索ページで検索を実行すると、検索に対するシンタックスを提供してもらえる。

Monitterを使って追跡する
Monitterは、特定のキーワードが含まれる大量のツイートをチェックすることが出来る、優れた無料のツールである。ツイッターのリアルタイムモニターと言っても過言ではない。
https://monitter.com にアクセスし、アカウントを作成する。
検索の用語を使って、カラムを作成する。
![]()
ここでは、4つのインテリアデザインの検索に対して、それぞれストリームを用意した:

次に特定の場所からのツイートを追跡する高度な設定を行う。

返信するべきツイートを見つけたら、Monitterから直接行動を起こすことが出来る。


その他のツイッター用ツール
他にもツイッターをモニタリングするためのツールは数多く開発されている。
https://ifttt.com – 複数のオンラインプラットフォームを一つにまとめ、作業を自動化する。
https://monitter.com/ – 複数のカラムを設定し、ツイッターの検索をリアルタイムで追跡する。
https://tweetmeme.com/ – 共有されることが多い、人気の高い記事を調べる。
https://trendsmap.com/ – 特定の場所でトレンドになっているアイテムを確認する – 役に立つビジュアルツール
https://tweetbeep.com/ – ブランド、自分、または、他の何かに関する全てのメンションをeメールで通知する(IFTTTに似ている)。
https://needium.com/ – 検索とメンションをモニタリングする。
ブラウザプラグインは、作業をスピードアップし、効率を高める上で大いに役に立つ。このセクションでは、グーグルクローム用のプラグインを幾つか紹介し、また、プラグインの高度な利用方法を少し指南する。
ブラウザプラグインのセクションでは、サイトのアクセシビリティ & インデクセーションの最適化に貢献するプラグインを紹介する。
まず、プラグインのリストを提供する。
これから、幾つかのプラグインの高度な利用法を伝授していく。
Broken Links Checker
このプラグインは、自分のサイトのリンク切れを発見することが出来るだけでなく、創造力を発揮して、他の人のサイトで実行し、リンク構築 & リンク候補の調査においてアイデアを得ることも可能である。
例えば、競合者のウェブサイトのサイトマップでこのプラグインを実行してみる。以下にその方法を紹介する:
1. 競合者のサイトのHTMLサイトマップを探す。この例では、適当に www.bizchair.com を利用した。サイトマップは次の通りである – https://www.bizchair.com/site-map.html
2. Link Checkerを実行する
エクステンショのアイコンをクリックする。

リンク切れが見つかるまで待つ – この例では、多くのリンク切れが見つかった。

「resource」ページにすぐに気がつくはずだ。楽にリソースのコンテンツを再現し、リンクを獲得するためにこのプラグインを利用することが出来る。
Chrome Sniffer
このプラグインは、自動的にウェブサイトが利用しているCMSまたはスクリプトのライブラリを表示する。例えば、ワードプレスのサイトのオーナーのみに接触したい場合、非常に便利である。
ウェブを閲覧していると、URLの右側のアイコンが利用されているCMSまたはスクリプトのライブラリに応じて変化する。
例えば、私のサイトはワードプレスで構築されていることが分かる。

このサイトはドルーパルをベースにしている。

Redirect Path Checker
このプラグインは、リダイレクトに遭遇すると、ユーザーに通知する。特に自分のサイトを閲覧している時に利用すると、古いURL(または外部のサイト)に内部リンクを張っている際に教えてもらえるため、とても便利である。
例えば、私のサイトでは、ギズモードの302リダイレクトにリンクを張っているリンクを発見した:

なぜ分かったかと言うと、プラグインから302に関する通知を受けたためだ。

このアイコンをクリックすると、ブラウザが当該のページに導く上で利用したリダイレクト(あるいは一連のリダイレクト)を表示する。

SEOmoz ツールバー & プラグイン
Mozのプラグインは様々な用途に利用することが出来る。その中でもより高度な方法を幾つか紹介していく:
リンクがfollowedかnofollowedかを速やかに特定する。

または、ウェブサイトの国およびIPアドレスを見つける。

プロキシとは何だろうか?また、なぜプロキシを利用するべきなのだろうか?
プロキシは、ユーザーとサーバーの間の仲介役のような存在である。要するに、プロキシを使って、ウェブ上で匿名で行動することが出来る。自分のIPアドレスではなく、プロキシのIPアドレスが表示されるためだ。これは、Rank Tracker等のローカルのソフトウェアを使ってランクキングをチェックしている場合、とりわけ有用である。自動でグーグル検索を何度も行い、当該のロケーションのランキングをチェックしていると、グーグルに危険信号を送ってしまうリスクを背負うことになる。プロキシを非倫理的な方法で利用している人達がいるが、私はこのような方法を推奨しているわけではない。しかし、自分のIPアドレスから、普段とは異なるアクティビティをグーグルに送ることなく、ランキングをチェックする方法として、うってつけである。
それでは、プロキシを利用する方法を伝授していく。多くの無料のプロキシアドレスを一度に見つけるあまり知られていない方法を私はマスターしている。
ステップ 1: 次のURLにアクセスする: https://www.rosinstrument.com/proxy/

無料の公開されたIPアドレスのリストが表示される。このリストは頻繁に変わるため、しばらくこの画面を開いていたなら、更新する必要がある。
ステップ 2: プロキシをScrapeboxにコピペし、テストする:
これは魔法のような効果をもたらす。プロキシのアドレスは、すぐに、そして、頻繁に利用することが出来なくなるため、全てのアドレスを一つずつチェックしていると時間を無駄に使ってしまうことになる。
「Manage」、次に「Test」をクリックする。数分後、プロキシのテストが終了する。続いての手順では、無駄のないリストを作成し、プロキシを選択していく。
ステップ 3: 良質なプロキシをメインのリストに戻す

「Export」の下の「Transfer Good Proxies to Main List」を選択する。すると、有効な無駄のないプロキシのリストが表示される。

ステップ 4: プロキシのアドレスをランキングをチェックするソフトウェアにコピーする
Rank Trackerでは、次のようにプロキシのアドレスを入力することが出来る:

しばらくするとアドレスは利用することが出来なくなるため、リストを再びテストし、次のURLからさらにコピペすることを薦める: https://www.rosinstrument.com/proxy/
おまけ: プロキシの代案
上述した方法は無料であり、それが最大のメリットである。しかし、もっと安定した取り組みを求めている場合は、バーチャルプライベートサーバー(VPS)を手に入れるとよい。大半のウェブホスティングサービスは、VPSを用意しているはずだ。これは、自分専用のIPアドレスを持つようなものだ。多少の料金を毎月求められる可能性もあるが、公開されているプロキシよりも強固であり、手に入れる価値はあるかもしれない。
既に究極のデータ収集マニアになっているはずである。しかし、まだ続きはある。次のチャプターでは、あまり利用されていないキーワードリサーチの方法を紹介する。
この記事は、Quick Sproutに掲載された「Chapter 5: Advanced Data Research」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










