![]()

![]()
Googleのピエール・ファーが、Google+のページで、Googleが新たなパンダアップデートをリリースしたと発表した。今回のアップデートには、「品質の低いコンテンツをより正確に特定する」上で効果的な新しいシグナルが含まれているようだ。
ピエール・ファーのGoogle+の投稿によると、今回のアップデートにより、「多様な小規模 – 中規模の品質の高いサイトが、上位にランク付けされるようになる」可能性があるようだ。これは前向きな変化だと言える。
新たに出願された特許には、フレーズに応じて、コンテンツのスコアをつける良質なアプローチが描かれている。この特許は、今回のアップデートと関係がある可能性があり、これから、検証していく。

サイトで発生しているn-gramを特定する 200
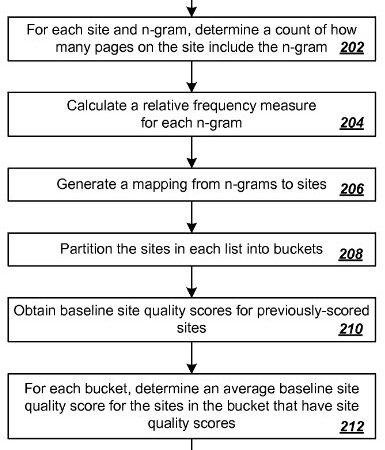
各サイトとn-gramに対して、n-gramを含むページの数をカウントする 202
各n-gramに対して、相対頻度の値を計算する 204
n-gramからサイトへのマッピング生成する 206
各リストのサイトをセグメントに分割する 208
過去にスコアを与えたサイトに対して、基準のサイト品質スコアを取得する 210
各セグメントに対して、セグメント内の品質スコアを持つサイトに平均の基準のサイトひんしつスコアを特定する 212
平均のスコアからフレーズモデルを生成する 214
パンダアップデートの最新版のリリースは、過去にパンダの攻撃を受けた一部のサイトにとっては、朗報だと言えるかもしれない。
そこで私は、バリー・シュワルツがSearch Engine Roundtableに投稿した記事「Google パンダ 4.1の展開が始まる – 小規模なウェブサイトの強い味方」にリンクが張られたフォーラムのスレッドを幾つかチェックしてみた。
あるスレッドで、投稿者は、9月19日にサイトのトラフィックが変化したと報告している。別のスレッドは、スパム & 質の低いコンテンツに狙いを絞っているのではないかと指摘していた。
そんな中、パンダアップデートの名前の由来となったナヴネート・パンダが、先日、新たに特許を出願していた。ナヴネート・パンダが発明者に名を連ねた最初の特許がリリースされた時、パンダに関連するのではないか(日本語)と私は考えた。パンダに対する数回のアップデート(そして、更新されるデータ)を考慮すると、少なくともアルゴリズムにもたらされた変化の1つは、この特許で描かれている可能性があった。また、コンテンツの品質のスコアリングにおける最新の更新は、現在、展開されているアップデートの要因となっていても、おかしくない。
それでは、当該の特許を紹介していく:
サイトの品質を推測する
発明: ユン・チョウ、ナヴネート・パンダ
米国特許番号: 20140280011
発表: 2014年9月18日
付与先: Google
申請: 2013年3月15日
概要
サイト、つまり、ウェブサイトの大体の品質を推測するためのメソッド、システム、コンピュータのストレージメディアにエンコードされたコンピュータプログラムを含む機器。
ある導入のケースでは、複数の過去にスコアを与えられたサイトに対して、基準となるサイトの品質スコアを取得する。
- 過去にスコアを与えられたサイトを含む複数のサイトに対して、フレーズモデルを生成する。フレーズモデルは、フレーズ固有の相対頻度の値から、マッピングを生成し、フレーズ固有の基準のサイト品質スコアを計測する。
- 過去にスコアを与えられたことがない新しいサイトに対しては、相対頻度の値をサイト内の複数のフレーズ一つ一つに取得する。
- フレーズモデルを経由し、新しいサイトのフレーズにおける相対頻度の値を用いて、総合のサイト品質スコアを特定する。
- 総合サイト品質スコアから、新しいサイトに対する予想品質スコアを特定する。
この特許は、フレーズアルゴリズムの利用を説明している。このプロセスでは、ページのコンテンツが、トークンに分類され(個別のワードと句読点等のアイテム)、ページ上のフレーズの頻度がカウントされ、各ページに対するスコアが計算されていく。
この特許は、フレーズベースのインデックスに関する特許(日本語)と比べると、「フレーズ」の定義を詳しく説明していない。また、実際に、Googleが、こういった特許を使っているかどうかは定かではないものの、その可能性は十分にある。
ページ上のトークンで現れたエラーは、正常化のプロセスで、無視されるのではなく、カウントされる。ただし、非常にレアなトークン(ウェブ上にほとんど存在しないワード)に関しては、この品質スコアの計算において、カウントされない可能性がある。
アンカーテキストは、向けられたページ上に実際に現れるフレーズとして処理される。これは、興味深い記述ではあるものの、特許の中では、その重要性は説明されていなかった。 結局、同じアンカーテキストを使ってページに向けられたリンクが多数存在する場合、特定のタイプのフレーズを数多く加えていることもあり得る。
トークンは、1, 2, 3, 4, 5トークン(ワードと句読点)のグループ、もしくは、n-gram(nには数字が入る)に分割されると見られる。Googleは、n-gram ビューワー等、別の方法にもn-gramを利用している。
Google Researchブログの記事「すべてのn-gramはあなたのもの」は、次のアイテムを含む、Googleで行われているn-gramを用いた複数の実験を説明している:
特許を読み、別の導入のケースを知りたい方は、特許にリンクを張っているので、確認してもらいたい。この特許は、パンダに対するアップデートとは関係のない、異なるスコアリングアルゴリズムを取り上げているのかもしれないが、それにしてはタイミングが良く、また、考慮する価値があると言える。
この記事は、SEO by the Seaに掲載された「New Panda Update; New Panda Patent Application」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










