![]()

![]()

SEOを理解する上での第一歩は検索エンジンの仕組みを知ることであり、それは、クロール・インデックス・ランキングの3ステップに大きく分けることができます。
SEOを考える上では、ついランキングのみに注視しがちですが、その前段階である「クロールとインデックス」にも注意を向けなければなりません。
あなたのサイトはきちんとGoogleに理解されているのでしょうか。その健全性(クローラビリティ)を測る上で重要となる指標をまとめたSearh Engine Journalの記事をご紹介します。
Webサイトのクローラビリティを最適化する目的は、検索エンジンが定期的にクロールに訪れ、新しいコンテンツが発見されるために、サイト内の重要なページを訪問してもらうことだ。
GoogleのボットはあなたのWebサイトを訪れるたび、可能な限りの範囲でページとリンクをクロールし、発見してくれる。しかし、上限に達した場合、それらはストップしてしまう。
あなたのページへの再訪問については下記のようなさまざまな要素が絡んでおり、それらに基づいて、GoogleはクロールするURLの優先順位を決定する。
基本的にあなたのサイトがGoogleの注意を引くのは、限られた回数のクロール内でのみ行われる。それは不定期であることも少なくない。Googleのクローラーが訪れた機会を有益に使うことが重要だ。
「クローラーにとって、あなたのサイトがどの程度最適化されているか」を分析するために、どこに着目すべきかを判断することは難しい。特に大規模なWebサイトや複数のWebサイトを担当している場合、他の優先すべきSEO施策があることも考えられる。
それこそが、今回の記事を執筆した理由だ。この記事ではクロールの健全性を確かめる上で非常に重要なポイントをその理由と共にリストにした。あなたが分析を開始する際の手助けになれば幸いである。
目次
こちらを算出することで、以下の項目が明らかになる。
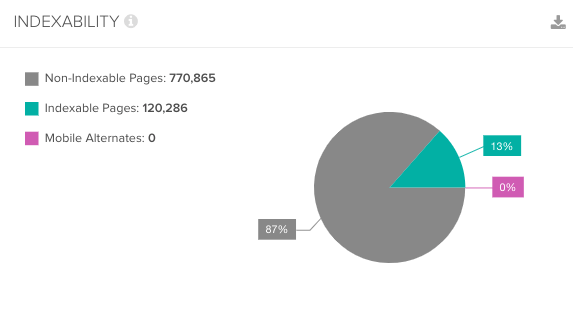
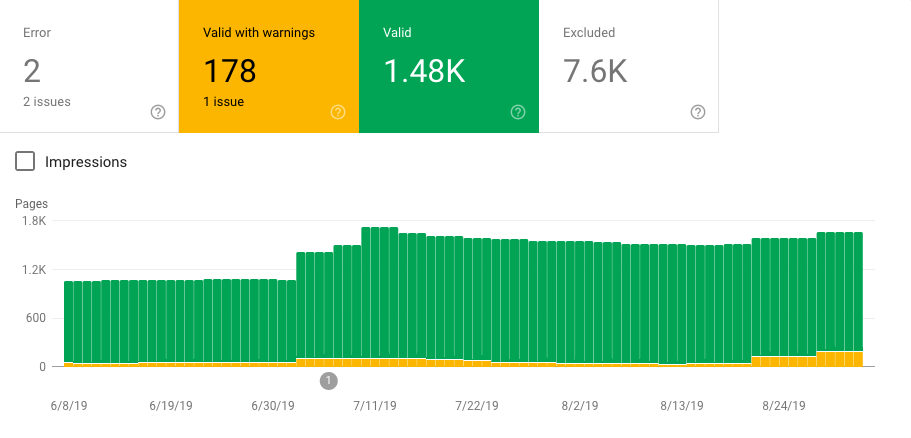
Googleのクロール活動とサイト全体のページ数とを比較することで、Googleがアクセスできないページ、または、定期的なクロールのスケジュールに組み込む判断に至っていないページがどのくらいあるかを深く理解することができる。
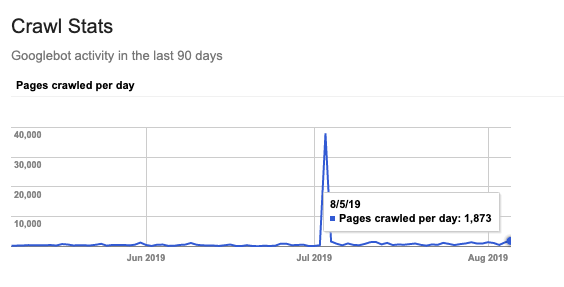
Googleボットがインデックスの不可であるページに滞在することは、クロールバジェットの観点から最適な状態であるとは言えない。
インデックス不可であるページへのクロール数を把握し、それらのページをインデックス可能な状態にすることができるかどうか、確認しよう。
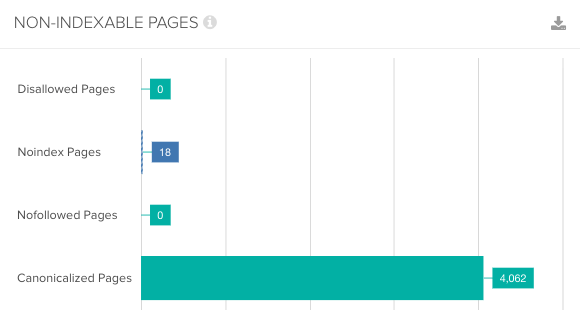
クロールをブロックしているページ数を把握することで、あなたがGoogleによるクロールを許可していないページ数を把握することができる。
インデックスの観点、また、さらに奥にあるページの発見性という観点において、それらのページが本当に重要ではないのか、あらためて考えてみよう。
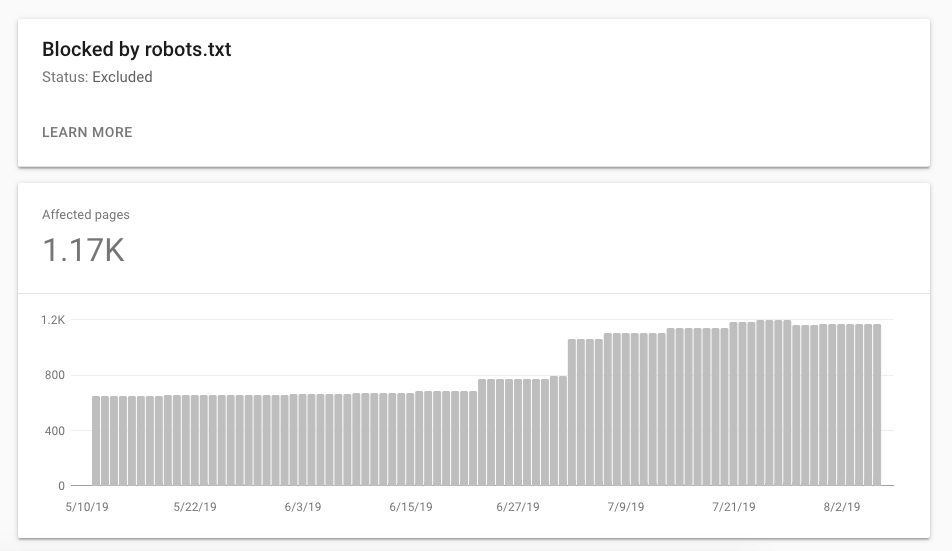
すでにGoogleにインデックスされているページを確認することで、あなたのサイト内のGoogleがアクセス可能な領域を把握することができる。
例えば、低品質であることを理由にサイトマップに含めていないページが、別の理由でGoogleに発見され、インデックスされている場合もある。
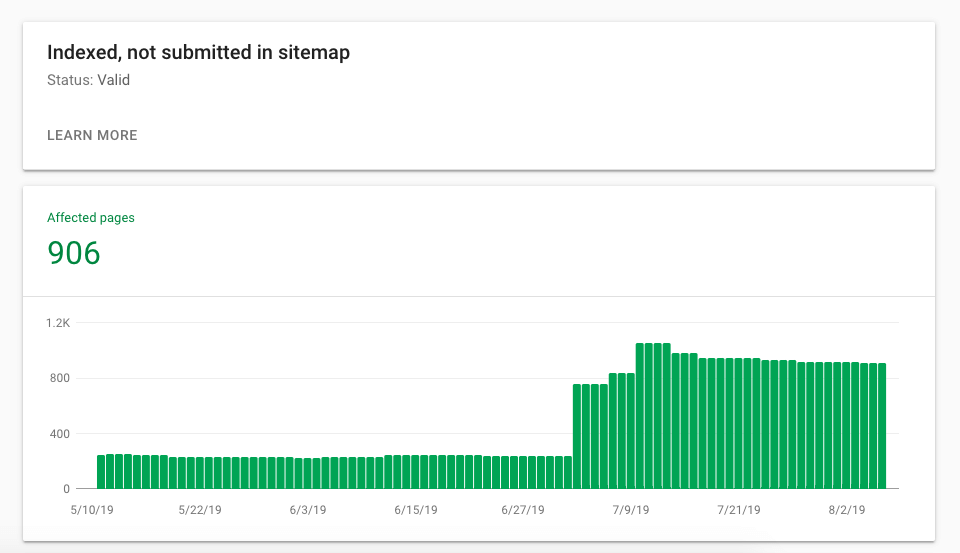
インデックスを望んでいるページではなく、エラーページへのクロールにより、クロールバジェットが消費されていないことを確認することは、非常に重要である。
Googleボットは404ページへも定期的にクロールする。それらのページが再公開されているかどうかを確認するためだ。
そのため、そのページを永久に閉じ、再クロールの必要がない場合は、410を設定するようにしよう。
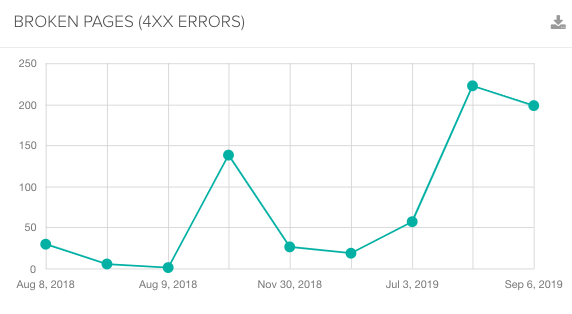
あなたのサイトでのあらゆるリクエストはクロールバジェットを消費する。そして、リダイレクトチェーンにおけるリクエストも、そのリクエストの範疇だ。
効率的にクロールできるようにGoogleを助け、クロールバジェットの消費を防ごう。そのためには、サイト内のリンクは200を返すページにのみ向けられるべきであり、最終目的地となるURL以外へのリクエストを発生しないようにしよう。
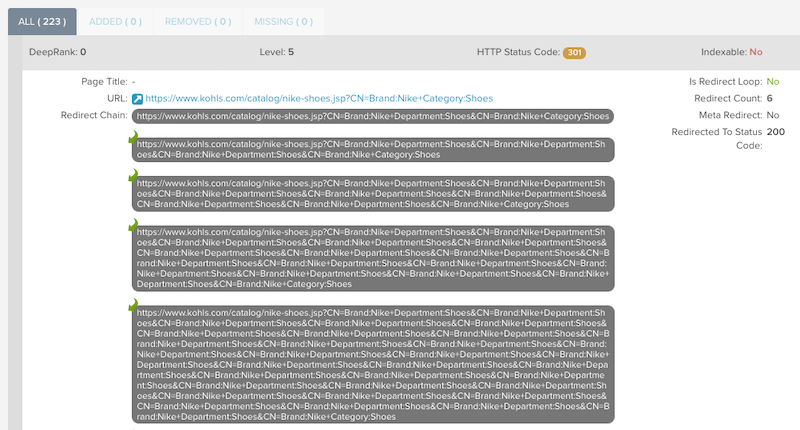
正規化されたページ数は、あなたのサイト内の重複ページ数を指し示している。canonicalタグは重複ページ間のリンク評価を統合してくれるものであるが、クロールバジェットの助けにはならない。
Googleは正規化されたページの中からインデックス対象のページを選ぶが、どのページが主要なページであるかを判断するため、対象のページすべてをクロールする必要がある。
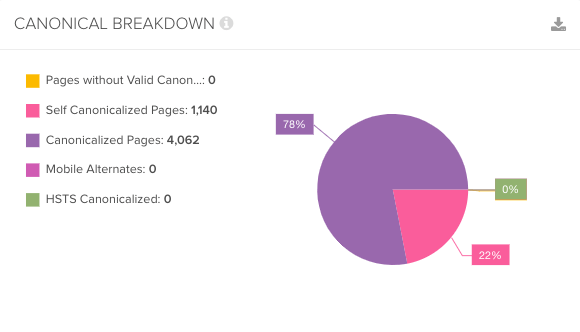
Googleは、まだ発見されていないページ、または、リンクされていないページのみをクロールする必要がある。
大抵の場合、ページネーションとファセットは、重複ページの原因となる。そのため、独自のコンテンツやクロールされるべきリンクが含まれていないことを確認しよう。
rel=nextとrel=prevは、もはやGoogleにサポートされていないため、ページの発見をページネーションに依存しないように、内部リンクの最適化を行おう。
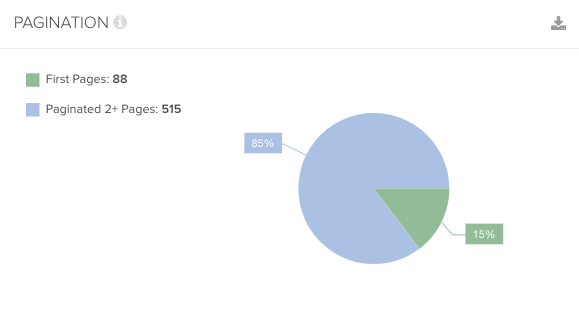
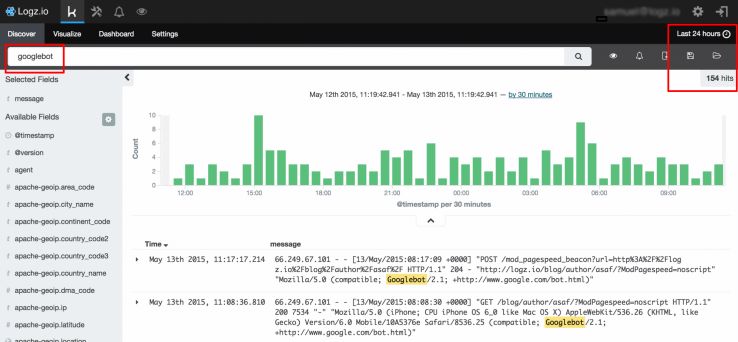
Google Analyticsのデータではユーザーによるアクセスがあるのに、ログファイルのデータでは検索エンジンによってクロールされていないという状況がある。これは、ユーザーによっては発見されているものの、Googleには発見されていないことが理由である。
複数のデータとクロールのデータを統合することにより、検索エンジンには発見されづらいページの存在が浮き彫りになる。
GoogleにとってのURLの発見の情報は大きく2つあり、1つが外部リンク、もう1つがXMLサイトマップである。Googleがあなたのページをクロールする際に障壁があり、Googleがすでに存在を認識し、定期的にクロールしているどのサイトからもリンクを得られていないのであれば、そのページがサイトマップに含まれているかを確認しよう。
今回の記事で紹介した10個のチェックポイントを確認すれば、クローラビリティへの理解と、サイトの技術的な健全性の把握につながるだろう。
無駄にクロールバジェットを消費しているページを発見できれば、ロボットテキストで指示するなど、Googleがそれらのページへのクロールを抑えるように指示することができる。
さらに、サイトの構造や内部リンクを最適化することで、重要なページへのクロールを促し、その重要性と発見性を高めることができるだろう。
クロールバジェット(注:俗称)の正確な数値を把握する術はありませんが、可能な限りの理解は努めるべきでしょう。
クロールはGoogleにとってもコストとなることからも、無駄なページをクロールされることはできる限り避けるべきです。まずは、明らかなエラーの箇所、重要でないページへのクロールの規制などを行い、順位や流入数への悪い影響がないことを確認しながら、徐々にその範囲を拡大していく、ということが王道の流れでしょう。
こうしたクロールの最適化において、非常に有効で利便性の高い記事でした。
SEO Japanでは、SEOやCRO(コンバージョン率最適化)を中心としたメールマガジンを2週に一度、木曜日に配信しています。
担当者のコラム(読み物)や、質の高い記事をピックアップして配信していますので、ぜひご購読ください。
なお、noteにてバックナンバーも公開していますので、ぜひ試し読みしていただければと思います。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










