![]()

![]()
先日、私はグーグルがHTMLのヘッダーの要素に関連するセマンティクスに注目する仕組み、ヘッダーにするコンテンツ、そして、検索エンジンがウェブ上の同様のヘッダーを持つこのようなコンテンツに注目して、これらのヘッダー内のワードやフレーズに与える重みを決めている仕組みをエントリで取り上げた。
当該の投稿はこの投稿の導入部分として綴っていたが、別のエントリとして独立させ、投稿したのであった。今回は、その他のHTML、とりわけリストとテーブルに関連するセマンティクスに注目していく。
今回のSEOの最重要特許ベスト10シリーズでは、複数の特許をまとめて紹介する。なぜなら、これらの特許は共に検索エンジンがセマンティクスの構造を用いて、ワードや概念がウェブ上で互いに関連し合っている仕組みを学ぶシステムを説明していると思ったからだ。幾つかの特許は古く、そして、1つの特許は最近公開されたばかりの審査中の特許である。また、グーグルの裏方と思えるプロセスを特定する上で役に立つホワイトペーパーも取り上げるつもりだ。この投稿ではグーグルに焦点を絞る予定だが、その他の検索エンジンでも同じようなプロセスが用いられていると言えるだろう。
グーグルセットは、ラリー・ペイジ氏による「より多くのリソースを少ない製品に与える」イニシアチブのおかげで今年の年明けに引退していた。しかし、このサービスは、グーグルで最も長期に渡って運営されていたベータサービスであり、最後の数年間はグーグルラボに置かれていた。
グーグルセットのプロセスはとても単純であった。同じセットのメンバーである可能性がある用語を入力すると、グーグルは当該のセットのその他のメンバーである可能性がある用語を返してくれる。
グーグルセットを支える特許は、自動的にリストを作成するシステムおよびメソッドであり、この特許は2003年に申請されていた。この特許の興味深い点は、ウェブからリスト形式の情報を抜き取り、ある程度関連している用語を見つける仕組みが描かれていることだ。これらのリストはHTMLのリストの要素に限定されていたわけではないが、フォームのようなリスト内でフォーマットされた以下のコンテンツを含む可能性がある:
グーグルはHTMLのリストのアイテムのフォーマットを活用していたが、それだけに依存していたわけではなかった。
このシリーズを企画し、どの特許を取り上げるべきか検討していた際、この特許は最初に思い浮かんだ特許の1つであった。ただし、私が2010年にグーグル、意味の近さをランキングシグナルとして特定で取り上げた際に反響が大きかったことが理由ではなく、グーグルがHTMLの要素のセマンティクスをどのように考慮しているかが分かりやすく描かれているためである。
簡単に言うと、リスト内の全てのアイテムの、そのリストのヘッダーへの距離は同じであると言うことだ。SEOについて、そして、検索エンジンが特定のフレーズに対するページの関連度を考慮する仕組みについて考える時、フレーズ内のワードが近ければ近いほど、そのフレーズに対して検索エンジンはより高い関連性を見出すと咄嗟に決めつけようとしてしまう。
しかし、リストのセマンティクスはこの考えを若干混乱させる。

リストのヘッダーは、<h2>等のヘッダーの要素の可能性もあるが、必ずしもそうでなければいけないわけではない。大きなファントを使うなどして、何らかの方法で通常のパラグラフのテキストを目立たせることも出来る。
また、この特許は、セマンティクスの距離をリストに限っているわけではない点も指摘している:
ヘッダーとタイトルに対して、用語間の単語の数に関わらず、文書のタイトルのある用語が、文書内のその他の用語にも近いと考えられることもある。同様に、ヘッダー内の用語がツリー構造内のヘッダーの下にあるその他の用語にとても近いと考慮されることもある。
従って、ページのHTMLのタイトルの要素内のワードはページの全てのワードと距離は同じなのだ。
ページ上のHTMLのヘッダーの要素内のワードは、見出しの全てのワードと距離は同じである。
明確なHTMLのセマンティクスの構造、もしくはコンマやHTMLの改行の要素 <br />で区切られているテキスト内のリストのような暗示的な構造をチェックするだけでなく、検索エンジンは、ページの異なる部分がどのように分類されていのかを理解しようと試み、これらの部分がお互い、そして、ページ上の別の部分とどのように関連しているのかを把握する。
グーグルの特許「文書の意味的に異なる部分を特定」は、グーグルがページをクロールする際、グーグルはウェブページの疑似的なレンダリングを行い、「文書のそれぞれの要素の大体の位置と大きさ」を特定して、文書の意味的に異なる部分を確認する可能性があると指摘している。
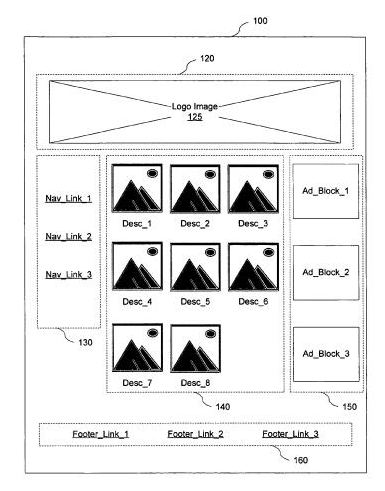
これらの部分、または、特許が“塊”と呼ぶアイテムは、検索関連の多数の用途で役割を与えられていると思われる。例えば:
リンク分析 – 異なる意味の部分のリンクに異なる重みが割り当てられると推測される。これはリーゾナブルサーファー(日本語)の特許の一つの特徴に似ている。
テキスト分析 – ページの異なる意味の部分の同じテキストには、場所に応じて異なる重みが割り当てられると考えられる。従って、クエリの用語が、フッターではなく、上の写真のイメージのブロックのセクションとマッチしている場合、当該のページにはフッターに見つかった場合よりも高いクエリスコアが与えられるはずであり、検索結果内でより高いランクが与えられる。なぜなら、イメージのブロックが配置されているメインのコンテンツの領域は、通常、ページへのビジターの第一のターゲットだからだ。
イメージのキャプション – イメージに近いテキストは、イメージから遠いテキストよりもイメージに関連している可能性が高く、イメージに対するキャプションを作るために用いられていると考えられる。これはイメージ検索等の用途で用いられると見られる。
スニペットの作成 – 塊ツリー内の塊には、疑似タイトルが与えられると考えられ、この疑似タイトルに応じて、ページの主要なトピックを記録し、少なくとも疑似タイトルを一つ含めることで、検索結果に対するページのより正確なスニペットが作成されている可能性がある。
グーグルセットでは、このアプリケーションに対して少なくとも2つか3つの用語を投稿すると、ウェブ上の明白なリストおよび暗示的なリストで表示される情報を集め、同じ一連の用語のセットに含まれる可能性のあるその他の用語をユーザーに伝えていた。一方、グーグルの“より多くのリソースをより少ない製品へ”アプローチの新たな犠牲者になるまで、グーグルウクエアードでは、例えば[Presidents of the United States]等の特定のトピックに対する検索を行うと、表形式で検索結果を返す取り組みが行われていた。このケースだと、1つ目のカラムは大統領の名前をリストアップし、2つ目のカラムは生年月日、3つ目のカラムは生まれた場所、4つ目のカラムは所属する政党が表示される。
グーグルセットのようにリストを探す代わりにグーグルスクエアードはウェブからテーブルの情報を取り出していた。このサービスは「names of the Presidents」のようにクエリに関連するテーマだけでなく、このテーマに関連する特徴も集めていた。
コミュニケーションズ・オブ・ジ・ACMの記事、「ウェブ上の構造化されたデータ(PDF)による、グーグルスクエアードを支えていたウェブテーブルズ(PDF)プロジェクトの説明は分かりやすく、それでいて、プロフェッショナルなレベルが保たれている。クロールを行い、テーブルのような構造で見つけたデータを理解する試みを行うことで、グーグルは次の取り組みのための手段を提供している:
グーグルスクエアードが返すスプレッドシートで表示されているデータは、複数のテーブルから情報を引き出す。大統領の生年月日は複数のウェブテーブルで見つかり、そして、大統領が所属する政党もその他の複数のテーブルで見つかる可能性があるためだ。
グーグルスクエアードは、テーブルの構造を活用していただけでなく、見つけたデータおよびアトリビュートに関連するテーブルからラベルとスキーマを学ぶことが出来た。グーグルは、このラベルを使って、グーグルがアトリビュート・コラレーション・スタィスティクス・データベース(ACSDb)と呼ぶアイテムを作成している。
ACSDbは特定のアトリビュートが特定のグーグルスクエアードのクエリに対して現れる可能性を計算する。
ウェブ上には「favorite color」等のアトリビュートをリストアップするテーブルが存在する可能性があるものの、それぞれの大統領の好きな色を伝えるウェブテーブルはあまり多くはないだろう。また、大統領の好きな色に関するテーブルのパブリッシャー達が協力しているとも考えにくいため、このアトリビュートがグーグルスクエアードで表示される可能性は低い。
ACSDbは、グーグルインスタントのクエリで行われる「オートコンプリート」に似た「オートスキーマ」の中で、データベースのデザイナー達に特定のタイプのアトリビュートを提案するために利用される可能性がある。
ACSDbは同義語の発見にも貢献する。テーブルに電話番号をラベルとして組み込むことに決めたなら、グーグルスクエアードは「phone number」の同義語として「phone-#」を提示すると推測される。
ウェブテーブルが抽出するデータの種類をもっと詳しく知りたいなら、次のホワイトペーパーに目を通しておいてもらいたい:
関連するアプリケーションとして、スプレッドシートをアップロードして、各種のビジュアル化ツールを使い、様々な方法でスプレッドシート内のデータを閲覧することが可能なフュージョンテーブルズが挙げられる。ウェブテーブルズとフュージョンズの双方に関わっている発明者の一人は、昨年8月にグーグルフュージョンに関してインタビューを受けていた: グーグルフュージョンテーブル。アロン・Y ハルヴィーにインタビュー
また、グーグルフュージョンは、異なるオーナーに属するデータセットを結合することが出来る。例えば、1973年以降の世界の地震活動と原子力発電所の場所を同じイメージの中で見ることが出来る。昨年の夏、数日前に起きたバージニア州の震源地であった街を訪れた際、地域の原子力発電所のサインを見て、訪問するのを躊躇ったことを覚えている。この視覚化を利用することも出来たはずであった。
ウェブで見かける多くのテーブルは、アトリビュートの名称が欠けているか、行に不適切なアトリビュートのラベルがつけられている可能性がある。2011年8月の末から9月の初めにワシントン州のシアトルで行われた第37回インターナショナルカンファレンス・オン・ベリーラージデータベースで発表されたグーグルの論文には、ウェブテーブルプロジェクト等のプロジェクトからデータが集められ、このような情報が欠けているテーブルにアノテーションをつける方法が描かれている。「ウェブ上のテーブルのセマンティクスを回復する(PDF)」が当該の論文である。
このアプローチを行う“理由”を次にあげる:
基本的には、コーパス内の各テーブルにセマンティクスを関連させ、セマンティクスを使って検索、ランキング、そして、テーブルの組み合わせを導くことが目標だ。しかし、ウェブ上のテーブルのスケール、範囲、そして、不均一性を考慮すると、ハンドコーディングによるドメインの知識に頼ることは出来ない。その代わりに、この論文では、自動的にウェブ上のテーブルのセマンティクスを回復する手法を説明する。テーブルがモデル化する一連のエンティティを説明するアノテーション、そして、テーブル内のカラムで提示されているバイナリの関係をテーブルに加える。
そのため、例えば、George Herbert Walker Bush’s favorite snack(ジョージ・H W・ブッシュの好きなスナック: ポークラインズ?それともポップコーン?)の検索が行われ、実際にこの類の情報を含むテーブルがウェブに存在するものの、その多くはラベルが貼られていない場合、用語「favorite snack」(好きなスナック)がテーブル上に表示されていなかったとしても、このセマンティクスの回復プロセスが当該の検索に対する結果をより多く返す上で貢献する。
この論文は、このセマンティクスを回復するプロセスを分かりやすく説明しているが、同じトピックの特許が今週公表されており、論文を共同で作成した人物の多くがこの特許でも発明者として名を連ねている。
回復したセマンティクスの情報を利用した検索
発明: Jayant Madhavan、Chung M. Wu、Alon Halevy、Gengxin Miao、Marius Pasca、Warren H. Y. Shen
米国特許申請番号: 20120011115
付与先: Google
公表日: 2012年1月12日
申請日: 2011年7月8日
概要
コンピュータの保存メディアにエンコードされたコンピュータプログラムを含む、回復したセマンティクスの情報を使ってテーブルを検索するためのメソッド、システム、そして、装置。
この文書の主題の一つの形態は、以下の行動を含むメソッドに組み込まれていると言える:
- テーブルの集まりを受信する。各テーブルは複数の行を持ち、各行は複数のセルを持つ。
- 集められたテーブルの各テーブルに関連するセマンティクスの情報を回復する。回復には、それぞれのテーブルの主題のカラムの特定を含む、クラスインスタントの層に応じたそれぞれのテーブルに関連するクラスの特定も含まれる。
- テーブルの集まりのそれぞれのテーブルに各クラスを使ってラベルを貼る。
グーグルは、同社の検索エンジンがウェブで提示されているコンテンツのセマンティクスを使って、当該のコンテンツをインデックスし、質問に答え、さらにはアトリビュートのラベルが欠けているテーブルのカラムにラベルを貼る仕組みを紹介する複数の特許や論文を公表し、さらには、複数のサービスを立ち上げていた。
グーグルがウェブで見つけたリストからコンテンツを抽出し始めた当初、グーグルはリストのセマンティクスの構造を活用して、どのワードが同じセットの一部としてフィットする可能性があるのかを把握していた。
リストのアイテムとリストに対するヘッダーの「セマンティクスの距離」、もしくはHTMLのタイトルの要素とページ上のワードの「セマンティクスの距離」、あるいはHTMLのヘッダーとヘッダーのコンテンツの「セマンティクスの距離」は、同じページに複数のフレーズを組み入れたいと望むコピライター達に影響を与える可能性がある:
例えば、このセマンティクスの距離のアプローチでは、以下の2つのリストのセットは含まれるフレーズに対してお互いに均等に関連していると推測される:
リスト # 1
bicycles
Schwin
Huffy
Coker
Gitane
Kona
Mongoose
リスト # 2
Schwin bicycles
Huffy bicycles
Coker bicycles
Gitane bicycles
Kona bicycles
Mongoose bicycles
グーグルは、ページ上のコンテンツの位置を確認するため疑似的なページのレンダリングを行うクローリングプログラムを用いて、ページの異なるセクションを見ている可能性がある。これらの場所は、場所に応じてセマンティクスの意味を持つことも考えられる。例えば、メインのコンテンツの領域はページのフッター内のリンクよりも大きな重みを持つと見られる。
グーグルは、レシピや評価用のスキーマ等、ウェブパブリッシャー達に様々なコンテンツの種類のラベルを提供してきた一方で、ウェブのテーブルで見つかったラベルを基にしたACSDbを構築し、アトリビュートのラベルを使ってテーブルのヘッダーが欠けているカラムに対するラベルを作成する等の取り組みを行うことが出来るようになっている。
皆さんはウェブページのセマンティクスの構造を十分に注意しているだろうか?
この記事は、SEO by the Seaに掲載された「10 Most Important SEO Patents: Part 7 – Sets, Semantic Closeness, Segmentation, and Webtables」を翻訳した内容です。
一読しただけではきちんと理解できない、時間をかけて読みこみたい内容でした。直接的にSEOに関係ない情報も多いですし基本はセマンティック構造を意識したコーディングとコンテンツ記述が大事という話に落ち着きそうですが、セマンティック検索が益々注目される今後、SEOと検索結果の未来を考えるためにも時間をかけて読みたい記事ですね。私も後でちゃんと読み直すことにします! — SEO Japan
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









