![]()

![]()
![]()

SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
「エンティティ」という言葉がSEOの文脈で見られ始めてから、10数年が経過しているのではないでしょうか?キーワード中心のSEOから脱却する際に避けては通れない概念ではありますが、なかなか理解が難しく、実務への活かし方も曖昧であるかもしれません。今回は「エンティティ」の解説に焦点を絞った、「Entity SEO Book: Moving from Strings to Things」の著者であるディクソン・ジョーンズ氏の記事を紹介します。

検索の歴史からエンティティとキーワードの違いまで、エンティティを正しく理解することにより、よりターゲットを絞った検索トラフィックの獲得が期待できる。
SEOの専門家でさえも、エンティティを正しく理解することに苦労している。さらに重要なことに、エンティティをSEOに活用すべきかという議論も活発に行われている。
こうした状況は、従来のSEOが単語やフレーズへのアプローチが中心であったことが理由であると、私は理解している。
実際、(私のような)検索の初期のころからSEOに携わっている専門家にとって馴染みのあるアルゴリズムには、「エンティティ」という概念を持ち合わせていなかった。コンテンツの作成、アンカーテキストの設置、検索結果のトラッキングなど、SEOの原則はキーワードが中心であった(大部分において、それは今も変わっていない)。そして、何が変わったのかを理解することが難しい人は多くいるのである。
しかし、ここ十年間で、検索は世界を、言葉の羅列として、また、相互に結び付けられた一連のエンティティとして理解するようになっている。
SEOにおけるエンティティを理解することは、将来を見据えた検索の戦略の土台となるものである。
また、生成AIやChatGPTにとっても重要なことである。
この記事ではその理由を説明する。具体的に扱うトピックは下記である。
目次
SEOの担当者であっても、キーワードとエンティティを混同してしまうことがある。
(検索用語としての)エンティティは、データベース内のレコードである。一般的に、エンティティは、特定のレコードを識別する。
Googleで言えば、下記といった具合だ。
「MREID=/m/23456」、もしくは、「KGMID=/g/121y50m4」
明らかに、これらは「単語」や「フレーズ」といったものではない。キーワードと混同してしまう根本的な理由として、下記の2つが挙げられるだろう。
つまり、我々にとっては、「エッフェル塔」は完全に識別が可能な「エンティティ」のように見えるが、Googleはそれを「KGMID=/m/02j81」と認識する。あなたが、「エッフェル塔」と呼ぼうが、「Torre Eiffel」と呼ぼうが、「ایفل بورجو」(アゼルバイジャン語)と呼ぼうが、Googleは気にしない。Googleは、あなたがおそらく、ナレッジグラフ内のエンティティを参照しているのだろう、ということを理解している。
これは、次のセクションにつながっている。
僅かではあるが、「A knowledge graph」と「The Knowledge Graph」と「The Knowledge Panel」には違いがある。
2005年、Metawebは、Freebaseと呼ばれるデータベースの構築を開始した。Freebaseは、「オープンで共有化された世界中の知識のデータベース」と表されている。
私は、Freebaseを、半構造化百科事典と認識している。
Freebaseは、「エンティティ(例えるならば、記事)」に、固有のID番号を付与した。そして、言葉による従来の記事としてではなく、このシステム内の他のID番号との関係を通じて、記事をつなげようとした。
資本金は5千万ドルで、5年後にはこのプロジェクトはGoogleに売却された。
商業目的の製品が開発されることはなかったが、Googleにとっての10年間に渡る、キーワードベースの検索からエンティティベースの検索への移行の基盤となった。
買収から6年経過した2016年、GoogleはFreebaseを公式に閉鎖した。なぜなら、こうしたデータベースの現代版である、「ナレッジグラフ」にそのアイデアを移行し、発展させたからである。
その際、Googleはエンティティのデータの多くをWikidataと同期させ、今後は、Wikidata(Wikipediaで使用されているデータの基盤)が、Googleのナレッジグラフと外界との橋渡し役の一つとして機能することを、公言している。
エンティティは主に、ある考えの曖昧さを回遍するために使用されており、同一のアイデアを有するページをランク付けするためには使用されていない。
これは、エンティティをうまく活用することが、あなたのWebサイトの順位に貢献しない、ということを意味する訳では無い。実際に、それは可能である。しかし、検索結果をユーザーに提供する際、Googleは正確な回答を提供することを何よりも心がけている。
必ずしも、最もふさわしいものとなるとは限らない。
それゆえ、文字列をエンティティへと変換するために、Googleは膨大な時間を費やしている。これは、あなたのWebサイトをインデックスする際、また、ユーザーのクエリを分析する際の、両方で発生している。
例えば、「エッフェル塔の近くにあるレストランの名前」と検索された際、Googleは、検索者が「名前」や「エッフェル塔」を探しているわけではないことを理解している。
ユーザーはレストランを探しているのだ。レストランであればどこでもいいわけではなく、特定の場所にあるレストランだ。この検索における2つの関連するエンティティは、「Champ de Mars, 5 Av. Anatole France, Paris(エッフェル塔の住所)」という文脈内の「レストラン」である。
これは、画像、マップ、Googleビジネス、広告、自然検索結果などをどのように混在させるかを、Googleが決定することに役立っている。
SEO担当者にとって最も重要なことは、Jules Verne(レストラン)が自身のWebサイトを、この検索と関連性があることをGoogleに伝えたいとした場合、このレストランのWebサイトがエッフェル塔の素晴らしい景色について言及することが重要である、ということである。
Jules Verneの場合、このレストランはエッフェル塔の内部にあるため、少々難しいかもしれない。
エンティティは検索エンジンに適している。なぜなら、エンティティは言語に依存しないからである。さらに、これは、エンティティが複数のメディアで記述することが可能であることを意味している。
エッフェル塔は象徴的な存在であるため、画像で説明することは理にかなっている。また、音声ファイルや公式ページも適しているだろう。
これらはすべて、エンティティの有効なラベルとして機能している。また、時には、他のナレッジグラフ内の有効な識別子としても機能している。
エンティティ同士の相互作用によって、SEOの専門家が、関連性のあるオーガニックトラフィックを獲得するための、一貫した戦略を作成することを可能としている。
エッフェル塔に関して最も「権威のある」ページは、公式サイトのページかWikipediaと言えるだろう。あなたがこれらのWebサイトを担当していない限り、この事実を覆すことは難しいはずだ。
しかし、エンティティ同士の相互作用によって、上位に表示されるコンテンツを作成することが可能となる。我々は、「レストラン」と「エッフェル塔」については述べてきた。しかし、「地下鉄」と「エッフェル塔」や、「割引」と「エッフェル塔」はどうだろうか?
エンティティが2つ存在することで、関連する検索結果の数は劇的に減少する。「地下鉄で旅行する際のエッフェル塔の割引」という検索を行うころには、「メトロのチケット」と「エッフェル塔のチケット」と「割引」が並列された、ごく僅かなWebページのみが対象となっているはずだ。
この検索が行われる回数は少ないだろう。しかし、コンバージョン率は非常に高いはずだ。
また、あなたのWebサイトにとって、非常に収益性の高いコンセプトであるかもしれない(この例は原則を説明するために用いた。こうした割引が存在するかどうかを調べている訳では無いが、きっと存在するはずだ)。
このコンセプトは、この検索における競合ページを、そこに含まれるエンティティとメインクエリに対する相対的な重要性を示す表に落とし込むことで、さらにその機会を拡大することが可能となる。
そして、この表が、競合ページよりも権威性のあるコンテンツを作成するための計画表として機能するのだ。
エンティティはランキングの要素ではないと、検索エンジンは主張するかもしれない。しかし、この戦略は、「品質の高いコンテンツを作成すれば、結果は自ずとついてくる」という考えの核心を表していると言えるのだ。
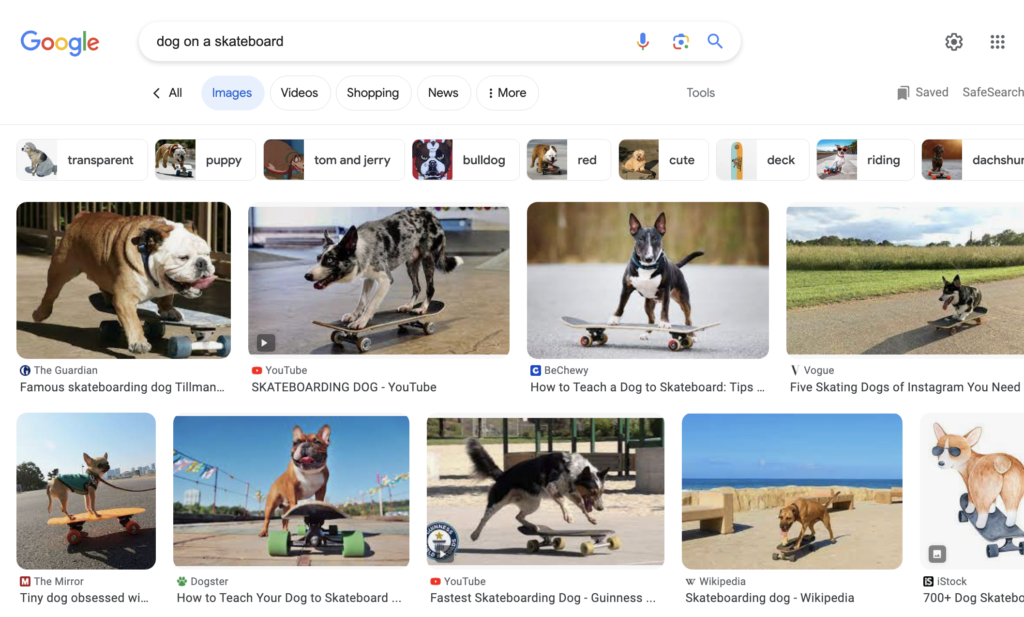
「dog on skateboard」の検索結果のスクリーンショット。Google、2023年8月。
エンティティは画像の最適化においても有益である。
Googleは、機械学習を用いた画像の解析に力を入れている。その結果、Googleは多くの写真において、メインとなるイメージを理解できている。
そのため、「スケートボードに乗っている犬」と検索した場合、コンテンツがその画像のサポートをすることで、ユーザーが検索した際に、より良く目にとまるようになる。
SEOの専門家によっても過小評価されているトラフィックの一つとして、Googleディスカバーが挙げられる。
ユーザーが積極的に何かを探していないときでさえも、Googleはユーザーにとって興味深いページのフィードを提供している。
Googleディスカバーは、Androidのスマートフォンか、iPhoneのGoogleアプリで使用することができる。ニュースがこのフィードに強く影響するが、ニュース以外のWebサイトもGoogleディスカバーからのトラフィックを得ることができる。
どのようにしてだろう?私は、エンティティが非常に重要な要素であると考えている。

Google Search Consoleのスクリーンショット。2023年8月。
Google Search Consoleに「Discover」タブがなくても、がっかりする必要はない。もし、「Discover」タブが表示されていれば、少なくともあなたのWebページの一つが、少なくとも一人のユーザーの興味と合致し、そのユーザーをターゲットとしたフィードに表示させることをGoogleが判断したということなのである。
上記の例では、ユーザーが積極的に検索を行っているわけではない状態でも、4.2%のクリック率があった。
これは、Googleがエンティティをマッピングすることで、多くのユーザーの関心や習慣とインターネット上のコンテンツを合致させているからである。
強い相関関係がある場合、Googleはユーザーにページを提供することができる。
2014年、Google(少なくとも、Googleの研究者たち)が、トピックを理解するためにキーワードを用いる考え方と、エンティティを用いる考え方を区別することに注力していることを示す論文が発表された。
この論文で、ダニース氏とグリック氏は、自然言語処理のシステムが、エンティティを基軸としたプロセスに移行していく方法を述べている。ドキュメント(Webページ)内のエンティティを定義するための、大規模なデータセットで使用される、バイナリ「顕著性」システムについて説明されている。
「バイナリ・スコアリング・システム」は、Googleが、該当のドキュメントが特定のエンティティについてのものであるか、もしくは、ないか、を判断する可能性を示している。
また、Googleは「顕著性」を0から1までの範囲で測定しているようである(例えば、NLP APIで与えられているスコアリング)。
いずれにせよ、「エンティティ」がページ内のどこに表示されれば「顕著」と言えるかについて、Googleの研究者たちが考えていることを知る上で非常に参考になると考えている。
詳しく内容を知りたいのであれば、この論文を読むことを勧めるが、この論文では「ニューヨーク・タイムズ紙の記事の研究としての顕著性」を分類した方法が記述されている。
具体的に見ていこう。
これは、エンティティが言及される最初のセンテンスである。
Webページの早い段階でエンティティについて言及することで、そのエンティティがその記事において「顕著である」とみなされる可能性が高まるかもしれない。
これは、そのエンティティが最初に言及された文章の「先頭の単語」が登場する回数である。
この記事では、「先頭の単語」が明確に定義されていないが、「単語を最もシンプルな形に連結したもの」、と私は理解している。
これは、エンティティの単語やラベルだけではなく、エンティティの参照(彼/彼女/それ)などの他の要素も意味する。
見出し内にエンティティが含まれている箇所。
「最初の言及の小文字の見出し単語」と説明されている。
この論文では、PageRankのバリエーションの活用にも言及している。また、WebページをFreebaseに置き換えた例も紹介している。
ここで共有されている例は、FEMA、共和党、オバマ大統領、共和党上院議員を含む上院議場での討論であった。
PageRankのような反復アルゴリズムをエンティティに適用させ、ナレッジグラフ内でこれらを近接させることで、ドキュメント内のこれらのエンティティの重要度の重み付けを変化させることを可能としている。
NLP、または、NEEP(Named Entity Extraction Program)が発見したドキュメント内のあらゆるエンティティ(もしくは、画像内のすべてのエンティティ)について、Googleに限らず、アルゴリズムが上記の全ての変数の値を作成している。
そして、スコアを付与するために、各変数に重み付けをする。論文内では、このスコアは1か0(顕著性があるか、ないか)に変換されるが、0から1の値である可能性が高い。
Googleがこれらの重み付けの詳細を公開することは決してない。しかし、この論文でも示されているが、この重み付けは、何億ものページが「読まれた」あとで決定される、ということである。
これは、大規模な言語学習モデルの性質である。
しかし、2つ以上のエンティティに関連するコンテンツの上位表示を狙っているSEOの専門家にとって、非常に大きなヒントがここにある。「エッフェル塔の近くのレストラン」の例に戻ってみよう。
いや、おそらく、これで全てではない(私の本を読んでいただいてもいい!)。しかし、著者やWebサイトのオーナーとして、全ての要素をコントロールできるわけではない。
しかし、コントロールできるもので重要な2つを挙げるとすると、文脈上で他のページからリンクを設置することと、それぞれの定義をすることに役立つSchemaを追加することである。
「about」と「mentions」のSchemaを使用することで、検索エンジンが曖昧さをなくす手助けをすることができる。
これら2つのSchemaのタイプは、そのページが何について書かれているかを説明することに役立つ。
1つか2つのエンティティに「about」を使用し、さらにいくつかのエンティティに「mention」を使用することで、SEOの担当者は、ナレッジグラフがすぐに理解できる形で、長い記事を重用な要素に集約することが可能となる。
しかし、Googleは、Schemaをコアアルゴリズムに使用することを明言しているわけではない。
私なら下記のSchemaをこの記事に追加するだろう。
<script type=”application/ld+json”> {
“@context”: “https://schema.org”,
“@type”: “WebPage”,
“@id”: “https://www.yoursite.com/yourURL#ContentSchema”,
“headline”: “Restaurants a small distance from the Eiffel Tower”,
“url”: “https://www.yoursite.com/yourURL”,
“about”: [
{“@type”: “Thing”, “name”: “Restaurant”, “sameAs”: “https://en.wikipedia.org/wiki/Restaurant”},
{“@type”: “Place”, “name”: “Eiffel Tower”, “sameAs”: “https://en.wikipedia.org/wiki/Eiffel_Tower”}
],
“mentions”: [
{“@type”: “Thing”, “name”: “distance”, “sameAs”: “https://en.wikipedia.org/wiki/Distance”},
{“@type”: “Place”, “name”: “Paris”, “sameAs”: “https://en.wikipedia.org/wiki/Paris”}
]
} </script>
Schemaを正しく選択することは、SEOの問題と同じくらい、哲学的な質問である。
しかし、「コンテンツを最適化する」ためではなく、「コンテンツの曖昧さを回避する」ためにSchemaを使用すると考えよう。うまく行けば、よりターゲットを絞った検索トラフィックが獲得できるかもしれない。
注:ディクソン・ジョーンズ氏は、「エンティティSEO:文字列からモノゴトへ」の著者である。
「エンティティ」の概念の説明や歴史、実作業への活かし方をまとめた記事でした。冒頭でも触れた通り、「エンティティ」を理解することはなかなか複雑な作業であるため、このような記事を複数読むことで理解を深めていければと思います。記事内でSchemaの使用を推奨する箇所がありましたが、「コンテンツを最適化する」ためではなく、「コンテンツの曖昧さを回避する」ためにSchemaを使用する、ということは非常に重要だと感じています。すぐに使えるテクニック、というわけではありませんが、SEOを深く理解するためにはこのような概念の理解も必要であると考えています。
この記事は、Search Engine Journalに掲載された「Entities In SEO: What Are They And Why Do They Matter?」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。