![]()

![]()
![]()

SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
Google検索の独占禁止法に関わる裁判は長い間行われているイメージがありますが、これら裁判の過程で公開された資料に注目した、Search Engine Landの記事(https://searchengineland.com/google-search-ranking-documents-434141)を紹介します。核心に迫る箇所は非公開になっていたり、数年前に使用されたであろう資料も含まれていますが、SEO担当者にとっては確かに興味深い記述があると感じています。明日、すぐに使える知識、というわけではありませんが、Googleの検索に対する考え方に触れることができる、よい機会であると考えています。
Googleの検索ランキングにおける3つの重要な柱について学ぼう。また、エンドユーザーのデータが担う重要な役割や、人々と検索のかかわり方についても学ぼう。
米国の司法省は新たな裁判資料を公開した。そこには、Googleの内部で使用されたプレゼンテーションやランキングに関係するドキュメント、Eメールなどが含まれている。
この記事では、Googleの検索ランキングの要素について記述されている、7つのドキュメントを紹介する。
目次
これは、Googleのエリック・リーマン氏がまとめたパワーポイントのプレゼンテーションを大幅に編集したものである。その他のドキュメントと同様、元の資料にあるべき完全な文脈は削られている。
しかし、その内容は、あらゆるSEO担当者にとって興味深いものである。
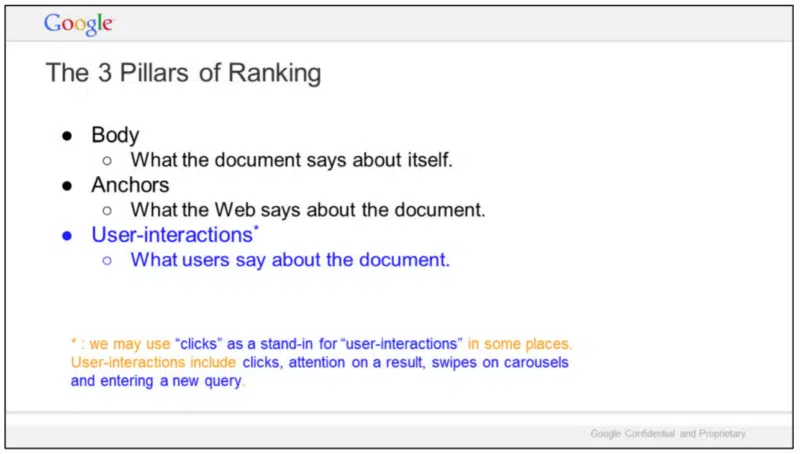
「ランキングの3つの柱」というスライドでは、下記の3つの領域が強調されている。
ユーザーインタラクションには、下記の注釈が加えられている。
あなたにとっても馴染みのあるものではないだろうか?マイク・グレハン氏は、このことについて、20年以上も記事を書き、公演をしてきた。その中には、「E-A-Tの期限:ページのコンテンツ、ハイパーリンクの分析、利用状況のデータ」という、Search Engine Landの記事も含まれている。
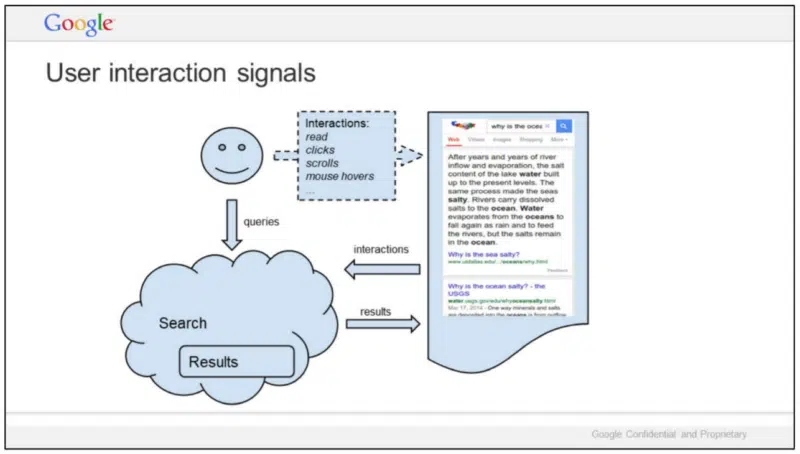
「ユーザーインタラクションのシグナル」と題されたこのスライドで、Googleは、クエリ、インタラクション、検索結果の関係性を、「海水はなぜしょっぱいのか?」という検索結果の具体例を伴って、説明している。Googleが示した具体的なインタラクションは下記である。
9月にリーマン氏は、Googleがランキングにクリック数を使用していると、独占禁止法の裁判で証言している。しかし、単純なクリック数だけでは、ランキングのシグナルとしては、ノイズが多すぎるという事実を忘れないでおこう(詳しくは、「リサーチのためのランキング(このセクションへのジャンプリンク)」のセクションを参照)。Googleは、クリック数を、トレーニング、評価、テスト、パーソナライゼーションなどに使用していることを公言している。
このドキュメントで編集されている箇所は、下記の通りである。
参照:Google presentation: Life of a Click (user-interaction) (May 15, 2017)
これら7枚のスライドは、リーマン氏によってまとめられた、「2016年第4四半期の総会」と題された、より大規模なプレゼンテーションの一部である。

このスライドでは、「我々はドキュメントを理解していない。理解しているふりをしているだけだ。」と述べている。
そして、Googleの「魔法」の秘密が明かされるのである。
まずは背景の説明から開始しよう。
1日に10億回、人々は我々に、クエリに関連したドキュメントを探し出すよう、依頼する。
おもしろいのは、我々は実際にドキュメントを理解していないということだ。基本的なこと以外、我々はドキュメントをほとんど見ていない。我々が見ているのは、人々だ。
そのドキュメントに対し肯定的な反応があれば、我々はそのドキュメントを良いドキュメントであると考える。反応がネガティブであれば、そのドキュメントは悪いドキュメントだろう。
極端に単純化すると、これこそが、Googleの「魔法」の秘密なのだ。
では、どのような仕組みなのだろうか?
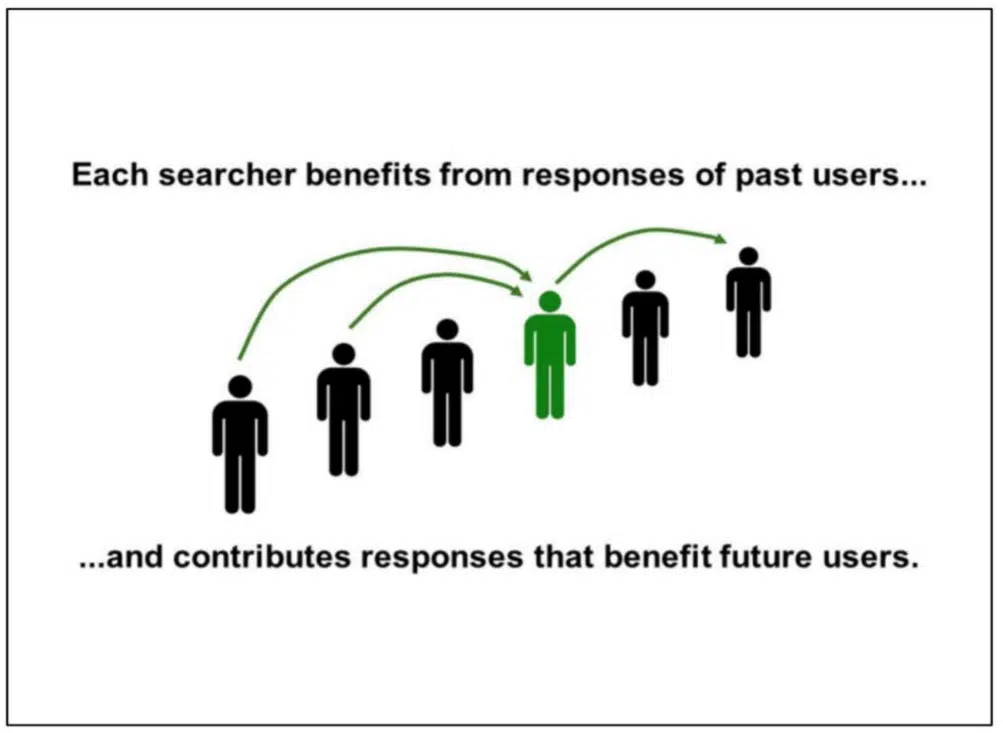
このスライドで、Googleはこのように説明している。「各ユーザーは、過去のユーザーの反応から利益を得ている。そして、未来のユーザーの利益となる反応を生み出している。」
検索は、誘導によって、機能し続けている。
これには重要な意味がある。
ユーザー体験を設計する際、ユーザーへの提供だけでは不十分なのだ。
我々は、ユーザーから学ぶことができるよう、インタラクションを設計しなければならない。
なぜなら、それが次の人への提供に繋がり、誘導を続けることで、我々がドキュメントを理解しているという幻想を維持することが可能となるからだ。
未来を意識しよう。ユーザーから学ぶことも、言語を真に理解するための鍵となると、私は信じている。

最後のスライドでは、Googleは下記のようにまとめている。
あなたが「検索は言語を理解し始めることに最適な場所である。成功は、検索を凌駕する意味を持つ。」ということに興味がなければ、他の4つのスライドは完全に無視してかまわない。
参照:Google presentation: Q4 Search All Hands (Dec. 8, 2016)
そのため、リンクはランキングにおける上位3つの要素ではないとGoogleが主張するのを聞くと、その理由がより深く理解できるだろう。もちろん、リンクは重要でなく、ユーザーデータがすべての理由である、と述べている訳ではない。機械学習と自然言語処理はその他の重要な要素ではあるが、詳しくは、「サンダー氏へのプレゼンテーション用の箇条書き(このセクションへのジャンプリンク)」のセクションで触れるとしよう。
Googleはエンドユーザーを注視している。つまり、ユーザーが検索結果とどのようにして関わっているかについてだ。そして、それは、個々人ではなく、全体として見ている。
このスライドの作成者はわからないが、非常に興味深い事柄が書かれている。

このスライドでは、検索の品質における18個の側面が記載されている。

このスライドではトラフィックのライブデータの評価における欠点について論じている。つまり、解釈が難しいという理由で、Googleは良いシグナルではないと述べているのだ。
観察されたユーザー行動と検索結果の品質の関連性は、とても脆いものだ。結論を出すためには大量のトラフィックが必要とされるし、個々の事例は解釈が難しい。
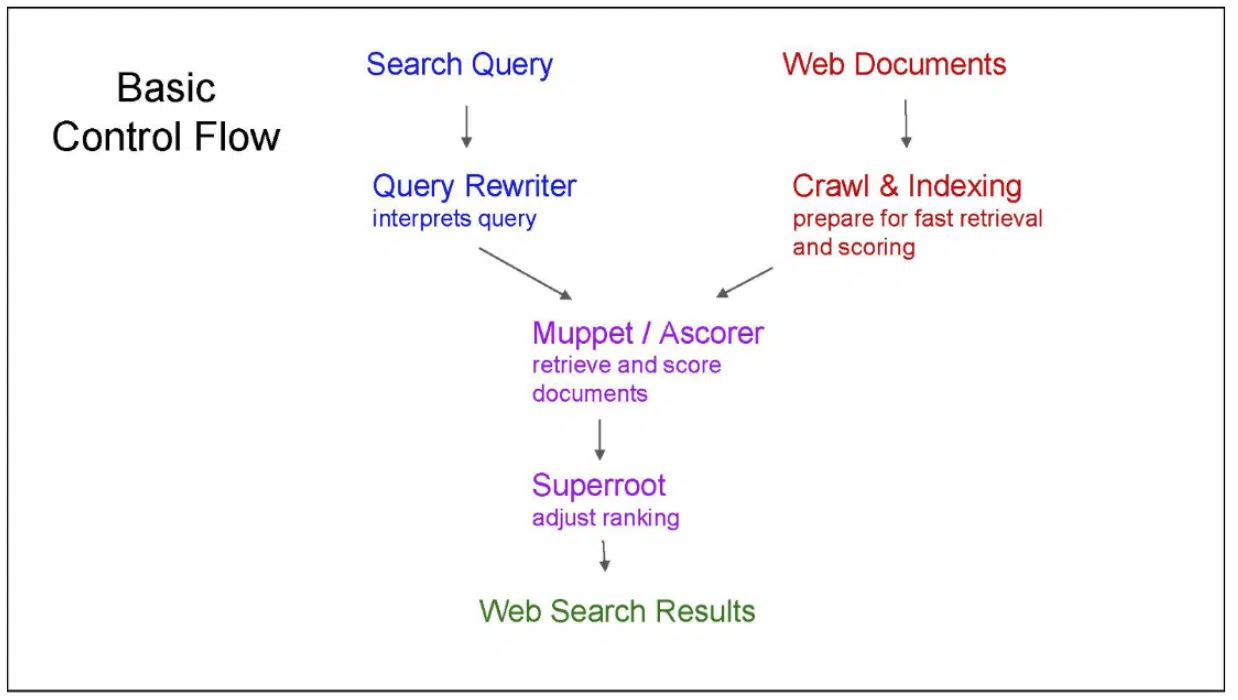
最後に、Googleの検索結果のランキングの仕組みについて、異なる描写を記している。
ランキングに関連しているわけではないが、このプレゼンテーションには、いくつかの興味深いトピックが記載されている。特に注目すべきは下記である。
参照:Google presentation: Ranking for Research (November 16, 2018)
このプレゼンテーションでは、検索が実際にどのような仕組みなのかを見ていこう。
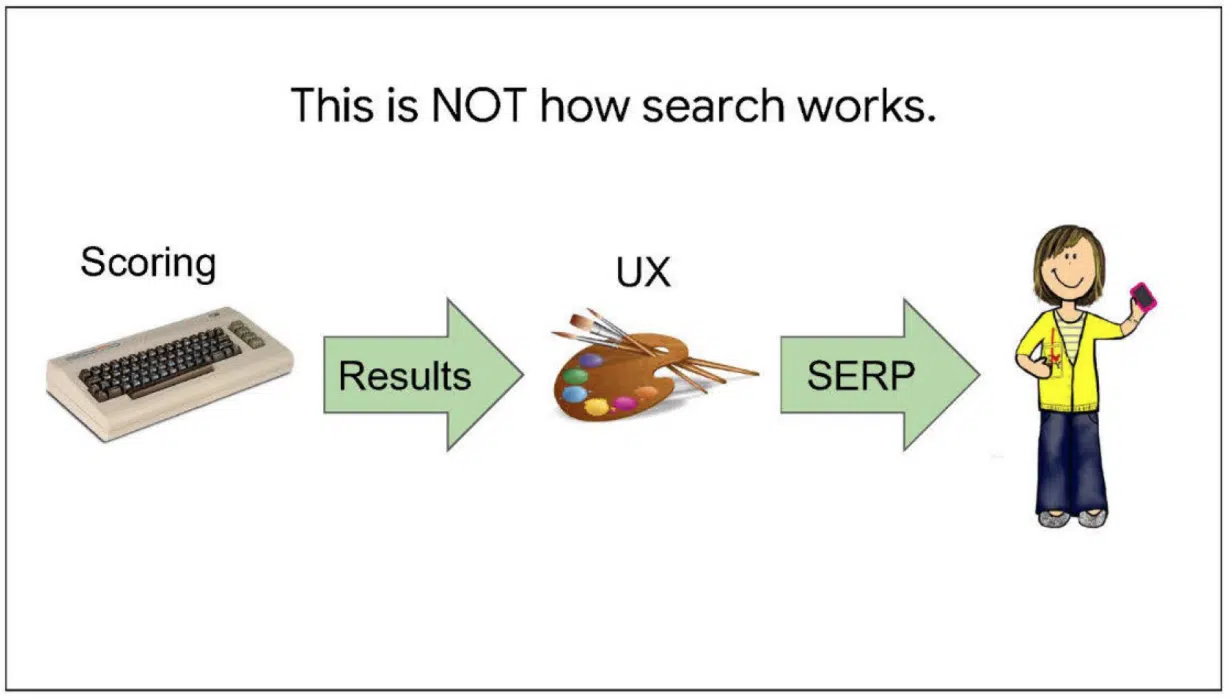
このスライドは、実際の検索の仕組みではないものを説明し、下記の記述が確認できる。
まず、我々はクエリを受け取る。複数のスコアリングシステムがデータを出力し、我々はUXを作り出し、それをユーザーに届ける。
これは間違いではなく、不完全である。不完全であるがゆえ、この方法で作られた検索エンジンはうまく作用しないだろう。魔法ではない。
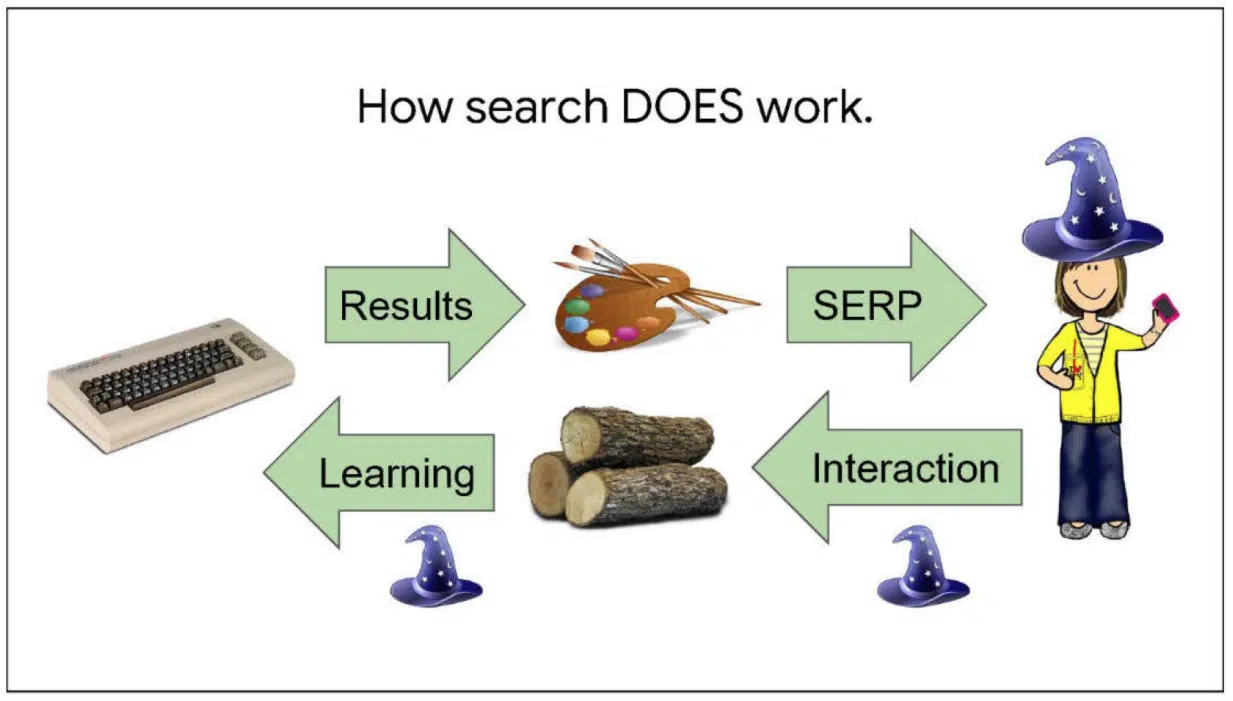
このスライドで、実際の検索の仕組みを学ぶことができる。
鍵となるのは、逆方向における、第二の情報の流れである。
人々が検索と関わる際、彼らのアクションが、我々に世界についての知識を与えてくれる。
例えば、クリックというアクションは、画像がWebの検索結果よりも優れている、ということを伝えてくれるかもしれない。また、特定の箇所を長く見ているということは、その箇所が興味深いということを意味しているかもしれない。
我々はこうしたアクションのログをとり、スコアリングチームが狭い範囲と一般的なパターンの両方でデータを抽出するのだ。

では、Googleはどのようにしてユーザーから多くを学んでいるのだろう?
一見すると、ユーザーが質問をし、Googleが答えている、という形だ。これが、我々の基本的なビジネスである。それを壊すことはできない。しかし、我々はひっそりと立場を入れ替えなければならない。下記に、例を挙げてみよう。
- 暗黙的に、ユーザーに質問する
- 必要な背景情報を与える
- ユーザーが我々に答えを伝える何らかの方法を与える
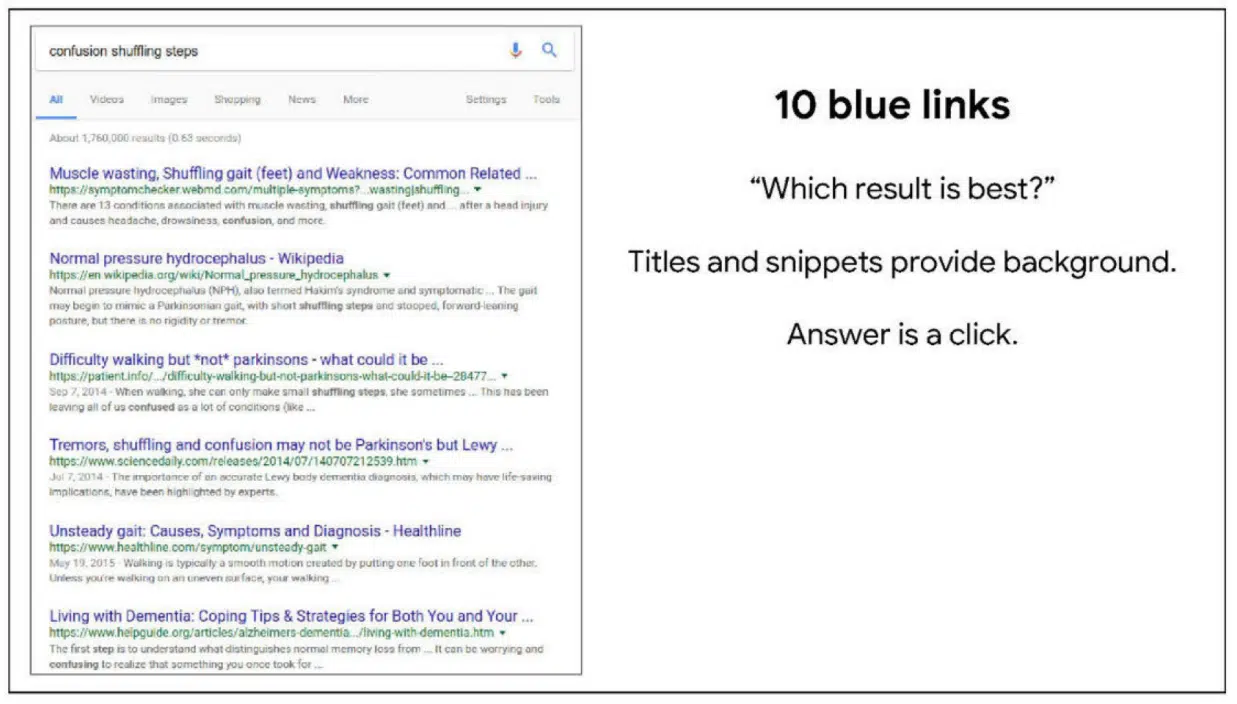
このスライドでは、10個の青いリンクについて言及している。
例えば、10個の青いリンクは、「どの結果が最適なのか?」という質問を投げている。
検索結果のプレビューは背景情報だ。そして、クリックが答えだ。
これは、優れたUXであり、多くを学ぶことができる。何年もの間、Googleは、つまらないUIで最高の検索結果を提供する、と馬鹿にされてきた。
しかし、このつまらないUIが検索結果を優れたものにしたのである。
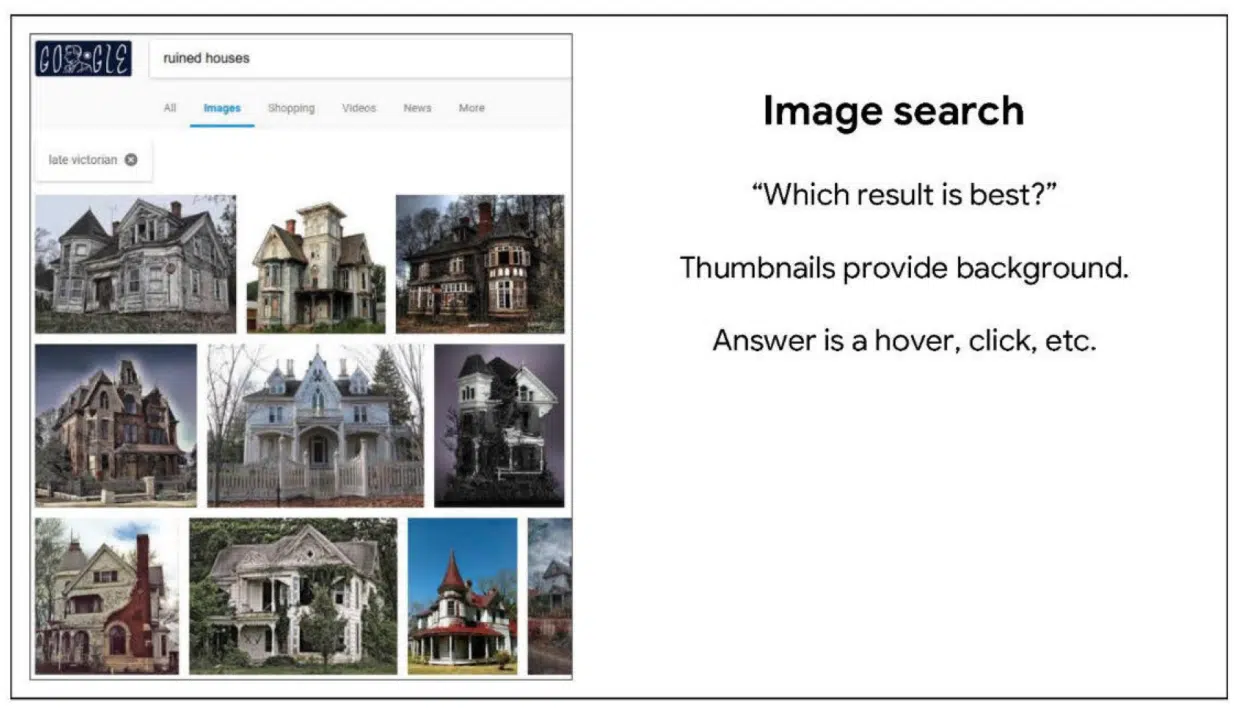
このスライドは、画像検索についてのスライドである。
画像も同様の質問を投げかけている。どれが一番のお気に入りなのか?サムネイルは背景情報であり、ユーザーの答えは、ホーバー、クリック、その他のインタラクションとして記録される。
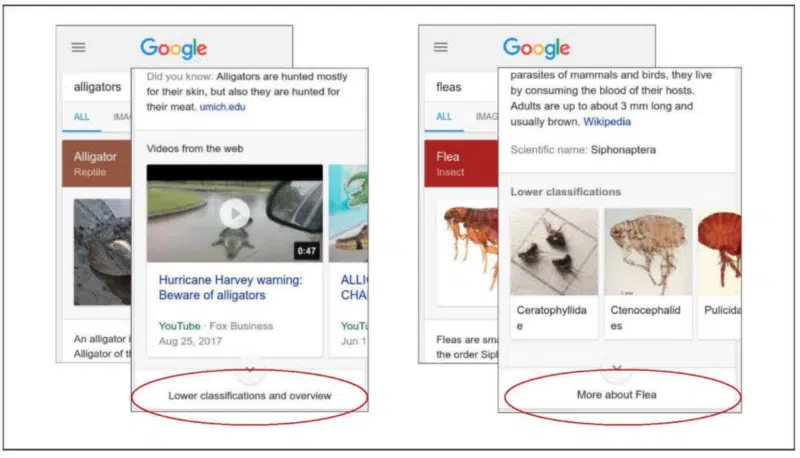
最後に、ナレッジカードについてのスライドを紹介しよう。
例えば、いくつかのナレッジカードは、追加でタップをしないと、完全に開かないものもある。
左の例の場合、追加のタップは、ユーザーがさらに詳しい分類と概要を求めていることを意味している。
右の例の場合、ユーザーは背景情報が足りていないことを意味している。
他になにがあるだろうか?ここでのタップは、スクロールダウンとどのような違いがあるのか?ユーザーは適切な判断ができない。そのため、タップとクリックには区別されるべきイベントとして記録される。そして、我々はその一つ一つに意味を持たせる必要があるのだ。
参照:Google presentation: Google is magical. (October 30, 2017)
このプレゼンテーションでは、ランキングと検索における、「ログが果たしている重要な役割」について論じている。
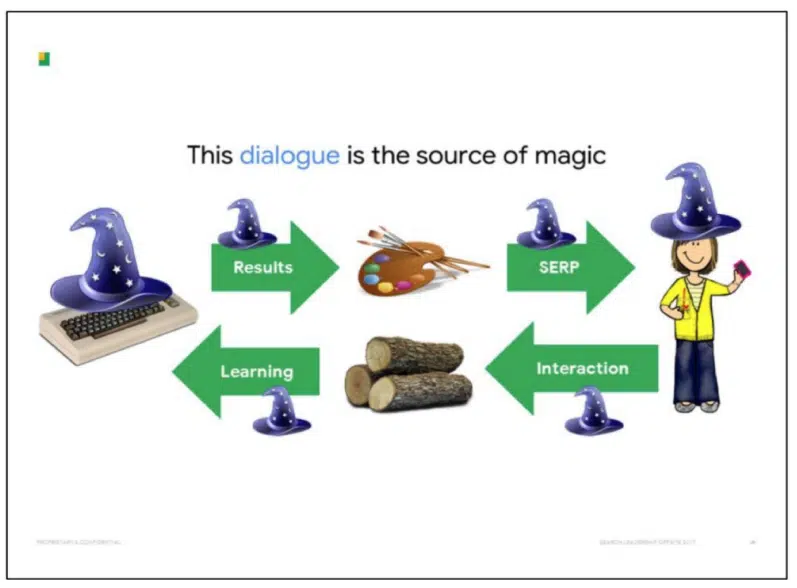
この見慣れたスライドは、Googleの魔法の源は、双方向の対話であるということを再度想起させるものだ。
検索は、皆が料理を持ち寄ってシェアをする食事会のようなものだ。これは、皆が様々な料理を楽しむことができる、素晴らしい取り組みである。しかし、この食事会は、皆が少しずつ協力して初めて、成功するものである。
これと同じように、検索も巨大な知識の集合によって支えられている。しかし、それは我々が作り出したものではない。検索に訪れる人々が、皆が活用できるシステムに対し、少しずつその知識を提供しているのである。

このスライドでは、Googleによるユーザー行動の解釈について論じている。このスライドには下記が記載されている。
ログには、この検索結果は良いものであり、この検索結果は悪いものである、というような明確な価値判断が含まれているわけではない。
そのため、我々はログに記録されているユーザー行動を、何らかの方法で、価値判断に変換しなければならない。
そして、この変換作業は非常に難しいものであり、15年以上、地道に研究されている。
こうした研究を行っている理由は、価値判断がGoogle検索の土台であるためだ。
我々が1つのセッションから僅かばかりでも何らかの意味を吸い出すことができれば、その翌日には10億倍もの価値を得ることができる。
その基本的な仕組みは、検索結果のこれが良い、これが悪い、これはあれよりも良い、という少量の「地上検証データ」から開始されるというものだ。
そして、関連するあらゆるユーザー行動を見て、「これはユーザーが良いと思うものであり、これはユーザーが悪いと思うものであり、これはユーザーが好むものである」と発言する。
もちろん、人々は、皆、異なり不規則である。そのため、我々が得ることができるものは統計的な相関関係のみであり、本当に信頼できるものは何もない。
例えば、
【非公開】
とあるユーザーが3つの検索結果をクリックした場合、そのどれが悪いものなのだろうか?3つの検索結果をクリックしたということは、そのクエリが難しいクエリであるだろうから、その全てが該当するだろう。ここでの課題は、最も有望なものを把握する作業である。

最後に、このスライドは、ログがランキングと検索をどのようにサポートするかについて論じている。このスライドには、下記の記述がある。
そして、ここからが私が警告した箇所である。私は何かを売っているのだ。ランキングチームのニーズを念頭においた上で、ログの用語のアイデアを売っているのだ。
しかし、基本的な理由として、ランキングチームは別の意味でもとても奇妙であり、それはビジネスへの影響でもあるのだ。
前述の通り、ランキングの中にはたった一つのシステムだけではなく、非常に多くのシステムが過去のログに基づいて設計されている。
これは、先程私がお見せした伝統的なシステムだけではなく、RankBrain、RankEmbed、DeepRankのような、すでに外部に公表している、最先端の機械学習のシステムも含まれている。
Webランキングは検索の一部に過ぎない。しかし、検索機能の多くがWebの結果を使用してクエリを解釈し、それに応じてトリガーを引く。
そのため、ランキングをサポートすることは、検索全体をサポートするということになる。
しかし、これに限らず、検索で開発された技術は、広告、YouTube、Google Playなど、会社全体に広がっているのだ。
つまり、私はファイナンスチームの一員ではないが、大雑把に言うと、Googleのビジネスの非常に大きな部分が、ランキングにおけるログの使用に関連していると考えている。
参照:Google presentation: Logging & Ranking (May 8, 2020)
このニュースレターは、モバイルのトラフィックがデスクトップの検索を凌駕する時期に出されたものであり、デスクトップとモバイルの検索ランキングの違い、ユーザーのインテント、ユーザーの満足度について掘り下げた内容である。
Googleは下記の指標の比較を行っている。
これをもとに推奨されているのは下記である。
このドキュメントの作者は不明であり、内容に驚くべき箇所はない。しかし、BERTと検索ランキングについての箇条書きは興味深いものである。
参照:Google document: Bullet points for presentation to Sundar (Sept. 17, 2019)
かなり昔のことになりますが、Googleの内部資料が公開(漏洩?)された際、それだけで大きなニュースになっていた時期がありました。その後、Googleも(可能なものに関しては)積極的に公開するようになったと感じています。この記事で扱われている資料についても、すぐに悪用されるような情報は含まれていません。検索の仕組みが進化しているという違いはあるかもしれませんが、「Googleの検索結果を簡単に操作することは不可能」という意識が浸透しているのかもしれないと思いました。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










