![]()

![]()
SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
初期のグーグルでは、検索を行った後に返される結果は、ウェブで見つかったページへのリンク、ページのタイトル、スニペット、そして、URLだけで構成されていた。その後、グーグルは次のようなタイプの検索を追加していった:
これらのサービスは別個の検索レポジトリとして立ち上げられたものの、統合されていった。そもそも、グーグルがはじめから独立のデータレポジトリとして提供するつもりではなかった可能性もある。2007年、グーグルはユニバーサル検索を導入した。2007年5月に発表されたサーチオロジーと呼ばれるプレゼンテーションで、グーグルは、動画、ニュース、書籍、画像、そして、ローカルの結果がウェブ検索結果に統合されたユニバーサル検索の告知を行った。グーグルの公式ブログによると、ユニバーサル検索は、2001年に行われた多くの取り組みから生まれたようだ:
数年間をかけ、100名以上の人々の力を借り、グーグルは、ユニバーサル検索への進化における第一歩を踏み出すため、インフラ、検索アルゴリズム、そして、プレゼンテーションメカニズムを構築しました。現在、グーグルは、新しいアーキテクチャを立ち上げ、画像、マップ、書籍、動画、そして、ニュースをウェブ検索に混ぜることで、google.comでのこの第一歩を提供しています。
この投稿でユニバーサル検索の初の特許に焦点を絞ることも可能ではあったが、異なるデータレポジトリの検索結果が現在の検索結果に含まれる仕組みがさらに詳しく説明された別の特許を取り上げることにした。この特許の詳細に進む前に、ユニバーサル検索の新しいバージョンが生まれた背景をもう少し詳しく説明しよう。
ユニバーサル検索が正式に発表された2007年から遡ること数年、グーグルは、検索エンジンによって表示されるウェブの結果に様々なタイプの検索結果を表示する取り組みを始めていた。検索コミュニティでは、検索結果への「バーティカルクリープ」と呼ばれていた。なぜなら、多くの人々はこのような別個のデータレポジトリをバーティカルな検索結果と呼んでいたためだ。より焦点が絞られた検索結果、つまりバーティカルな結果が忍び寄る(クリープ)光景を表現していた。
2006年、私はバーティカルクリープを「グーグルの通常の検索結果に進むバーティカルクリープ化」の中で取り上げた。これらの結果は、イメージやニュースは上部に、ローカルな結果はページの4番目の位置に等、特定の場所に表示されていた。
このような結果での実験に加え、グーグルは、適切だと判断した場合、ワンボックスの結果も表示することがある。その例を幾つか挙げる:
グーグルがワンボックス内で表示する結果を判断する仕組みに関しては、サーチエンジンランドに投稿した「グーグルのワンボックスを説明する特許」の中で詳しく説明している。このアプローチを描く特許(付与済み)は、望まれるレポジトリの判断(米国特許番号 7,584,177)であり、ユーザーの行動データを多用して、ワンボックスで表示するアイテムを決める仕組みを説明している。サーチエンジンランの記事でも指摘したように:
この特許を私が正しく理解しているとすると、異なるバーティカル検索内のクエリに関するユーザーのデータは、ワンボックスの結果に現れる文書や情報に影響を与える可能性がある。従って、グーグルの画像検索で「ライオン」の写真を探しているユーザーが多いなら、ワンボックスはライオンのイメージを表示すると推測される。グーグルニュース検索で大勢のユーザーが突然「ライオン」を検索する場合、イメージの代わり、もしくはイメージに加えて、ワンボックスのエリアにニュースの結果が現れると考えられる。
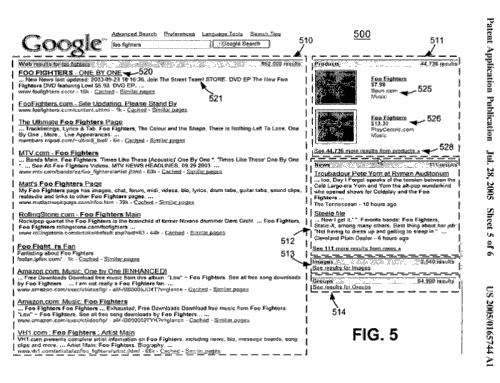
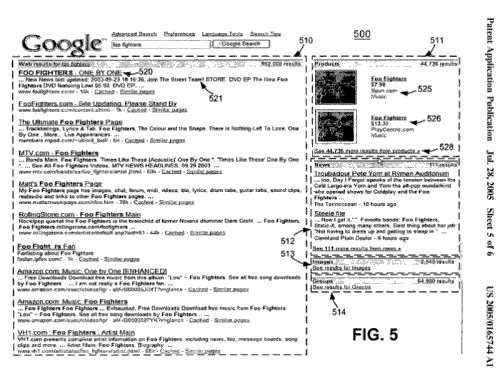
ユニバーサル検索の第1弾の特許が2005年7月に公表されたとき、この特許は、異なるタイプの検索結果を、下のスクリーンショットに掲載されているように、ウェブの結果を左に、そして、右のボックスには上から順番に製品検索、ニュースの結果、リンク付きのイメージのセグメント、そして、リンク付きの“グループ”の結果を分割する検索結果について説明していた。
カテゴリーの一部は、検索の関連性もしくは検索の意図を読むことで、その他のカテゴリーよりも深く関連していると見られる可能性がある。この特許は次のように説明している:
例えば、ランキング要素の402は、通常検索クエリをリスト内の文書の内容と比較して、ランキングの値を比較の距離に応じて決める。
「buy athletic shoes」(スポーツシューズを買う)と言う検索クエリについて考えてもらいたい。この検索クエリでは、ランキング要素の402は、ユーザーがセール中のスポーツシューズに興味を持っていると推測されると判断するだろう。
従って、ランキング要素は“製品”カテゴリーを上位に格付けすると見られる。その結果、製品カテゴリーに該当するリンクのリスト内のリンクとして、セール中のシューズを提供しているウェブページに向かうリンクが選らばられる可能性が高い。
このユニバーサル検索の特許は、2008年に付与されていたが、グーグルが検索レポジトリから表示する結果を判断する仕組み、そして、表示する仕組みを説明する取り組みは恐らくこれが最後ではない。
半年後に公表されたヤフー!の特許もまた、ヤフー!が「過去の選択のデータ」に応じて、異なる検索レポジトリに対する検索結果で検索ユーザーに提示する結果を判断する仕組みを示唆していた。
ユーザーの選択は、データレポジトリから提示する結果を選ぶ上でいまでも大きな影響力を持っていると思われるものの、2008年6月に米国特許商標局で公開された新しい特許にも、異なるタイプのデータの関連性が、この判断において考慮される仕組みに関する詳細な情報が提供されている。私はこの特許をグーグルのユニバーサル検索と結果のブレンドが行われる仕組みの中で紹介した。
この新しい特許の発明者の一人として名前が挙がっているデビッド・ベイリー氏は、1年近く前にグーグルの公式ブログに投稿した「ユニバーサル検索の舞台裏」の中で過去のユニバーサル検索の問題点を幾つか挙げていた。この投稿の中で同氏は次のように述べていた:
私達が抱えていた難題を簡潔に説明しよう。今までは、グーグルはニュース、書籍、ローカル、そして、その他の検索結果をこの[trends in education]にあるようにページの上部にしか表示することが出来なかった。しかし、検索結果の上部に結果を掲載するのは難しいため、たとえ有益であったとしても、グーグルはこれらのタイプの結果を表示する行為を避けることが多い。このような結果をページの別の場所に巧みに配置することが出来れば、これらの優れたグーグルの機能のメリットをユーザー達ともっと頻繁に分かち合うことが出来るのだ。
表示するべき追加の結果、そして、ウェブ結果の配置場所の判断は、この特許申請の主なテーマであった。この特許「検索結果をインターリーブする」は2011年12月に付与されていた。
簡単に言うと、ユーザーがクエリをグーグルに送ると、ウェブページに対する検索結果、そして、その他のデータレポジトリからの検索結果が返される。その他のレポジトリの検索の品質スコアは、過去の選択のデータ、または当該のレポジトリに相応しい独特のスコアリングの特徴、もしくはその双方を基に決められると推測される。例えば、グーグルニュースの結果の特有のスコアリングの特徴には、ニュース記事の新鮮さが含まれると見られる。また、グーグルは、特定の期間内に特定のニュースの結果が選ばれる頻度にも注目している可能性はある。画像の結果においては、グーグルは、画像の解像度や大きさ等の特有のスコアリングの特徴を採用していると考えられる。
これらのその他のレポジトリの異なるカテゴリーの上位の結果が、ウェブ検索結果に対して考慮され、そして、恐らくブレンドされるのではないだろうか。複数のソースからのブレンドが行われると、混合されたプログラムは検索の品質スコアを再計算するものの、異なる検索エンジンの結果に対する“特有のスコア”を減じる可能性がある。例えば、画像の大きさや解像度は、当該の画像の格付けにおいてあまり重要視されないこともあり得る。このように、検索ユーザーに表示される最終的なブレンドされた結果は、アップルとオレンジを比較するような結果にはなりにくいと見られる。
ウェブ検索結果以外の結果をウェブの結果にまとめる戦略的なアプローチは複数存在する可能性がある:
「ユニバーサル」な検索結果を提供すると言うアイデアは、画像や製品検索等のその他のバーティカルの検索レポジトリを導入する以前からグーグル社内では提案されていた。
様々なタイプの結果を提供する試み、そして、このような結果に対して検索ユーザーの意図にマッチさせる取り組みは、ユニバーサルな検索結果を提示する主な理由の一つに挙げられると思われる。
ウェブ検索で表示される可能性のあるウェブ結果以外の検索結果は、画像検索、製品検索、そして、ニュース検索等の異なるタイプのデータレポジトリから選ばれる。これらの結果のランキングは、特定のレポジトリの特有なランキングの特徴を一部参考にしている。そのため、ウェブの結果以外の検索結果をグーグルの自然な結果で表示してもらいたいとユーザーが望む場合、これらの結果は、それぞれのレポジトリに特有の特徴を基に上位に格付けされるべきである。
このようなウェブの結果以外の検索結果が選ばれると、ウェブの検索結果に対して、各レポジトリ特有の特徴への重みが減らされた状態で再び格付けされる。そして、このランキングは(上述した一部の戦略的な検討事項を参考にして)、ウェブの検索結果で表示するかどうか、また、どこに表示するかを判断する可能性がある。ユーザーのクリック数も重要な役割を持つと思われる。例えば、ニュースの結果が大量のクリックを獲得しているニュース記事は、クリックが少ないアイテムよりもウェブの結果に表示される確率は高いと推測される。
この記事は、SEO by the Seaに掲載された「10 Most Important SEO Patents: Part 9 – From Ten Blue Links to Blended and Universal Search」を翻訳した内容です。
Googleが現在のユニバーサル検索に至るまでの歴史と各種技術が良く分かる「これであなたもユニバーサル検索通」的な記事でした。必要に応じてウェブ検索以外の各データレポジトリから情報が抽出され、ウェブ検索と比較評価された上で最終的に検索結果ページに表示される、と。いわれてみれば当たり前ですが、改めて説明されると、深く理解した気になってしまう私でした。 — SEO Japan
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










