![]()

![]()

SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
この記事は、2025年 5月 27日に Search Engine Land で公開された Duane Forrester氏の「Inside the AI-powered retrieval stack – and how to win in it」を翻訳したものです。

従来のリンク順位中心型検索は終焉を迎えつつあり、新しいAIベースの検索技術(検索スタック)が主役となる時代が始まった。
本稿では「ベクトルデータベース」「ベクトル化」、そして「逆順位融合(Reciprocal Rank Fusion)※」が、検索スタックをどのように変えたのかをご紹介します。
※逆順位融合(Reciprocal Rank Fusion):複数の検索結果ランキングを統合する手法。RRF。
人々が「サングラス」についてどのように検索するか、想像してみてください。
従来の検索モデルでは、ユーザーは「最高のスマートサングラス」と検索し、SERP(検索結果ページ)に表示されたリンクを順に確認していきます。
一方、新しい検索モデルでは、ユーザーは「Ray-Ban Metaグラス※って何?」のように質問を投げかけ、SERPに表示されたリンクを一切見ることなく、仕様、使用例、レビューなどを含んだ総合的な回答を得られます。
※Ray-Ban Metaグラス:メガネ型のデバイス。アイウェアブランドのRay-BanとFacebook、Instagramなどのサービスを運営するMeta社が共同開発したスマートグラス。
この変化は、新時代の到来を告げています。コンテンツは、もはや単に検索結果で上位に表示される必要はありません。
「検索されること」「理解されること」そして「回答として組み込まれること」が求められるのです。
かつてのSEO戦略は、ページを作成して、GoogleやBingがクロールしてくれるのを待ち、キーワードが検索クエリに一致することを祈りつつ、広告が表示されないよう願うというものでした。しかし、このモデルは静かに崩れつつあります。
生成AIによる検索システムでは、ページが検索結果にリストされる必要すらありません。
重要なのは、そのページが構造化され、AIにとって解釈可能であり、必要なときに情報として利用できる状態になっていることです。
これが新しい検索スタックです。リンク、ページ、ランキングといった従来の要素ではなく、ベクトル、ベクトル表現(Embedding)、ランキング融合、そしてランキングではなく“推論”によって機能するLLM(大規模言語モデル)を基盤としています。
もはやページ単体を最適化するだけでは不十分です。
どのようにコンテンツを分割し、意味ベースでスコアリングし、再び組み立て直すか──そのプロセス全体の最適化が求められます。
そして、この新しいパイプラインの仕組みを理解すれば、従来のSEO施策がどれほど古風に見えるかが分かるはずです。(ここで紹介するのは簡略化したパイプラインです。)
目次
すべての最新の検索拡張AIシステムの内部には、ユーザーからは見えない“検索システムの技術スタック”が存在します。
これは従来の検索システムとは根本的に異なります。
文、段落、またはドキュメントは、その「意味」を数値化した高次元のベクトルに変換されます。
これにより、AIは単なるキーワードの一致だけでなく、「意味の近さ」によってアイデアを比較できるようになります。そのため、正確な語句を使っていなくても、関連性の高いコンテンツを見つけ出せるのです。
これらのベクトル(埋め込みデータ)は、ベクトルデータベースに高速で保存・検索されます。
代表的なものとしては、Pinecone、Weaviate、Qdrant、FAISSなどがあります。
ユーザーが質問を入力すると、そのクエリもベクトルに変換され、データベースから最も近い意味のチャンク(断片)が数ミリ秒以内に返されます。
昔ながらのアルゴリズムですが、今なお極めて実用的に使われている検索アルゴリズムです。BM25はキーワードの頻度と希少性に基づいて、コンテンツの関連度を評価します。
特に、ユーザーがニッチな用語を使用したり、正確なフレーズ一致を求める場面において、高い精度を発揮します。
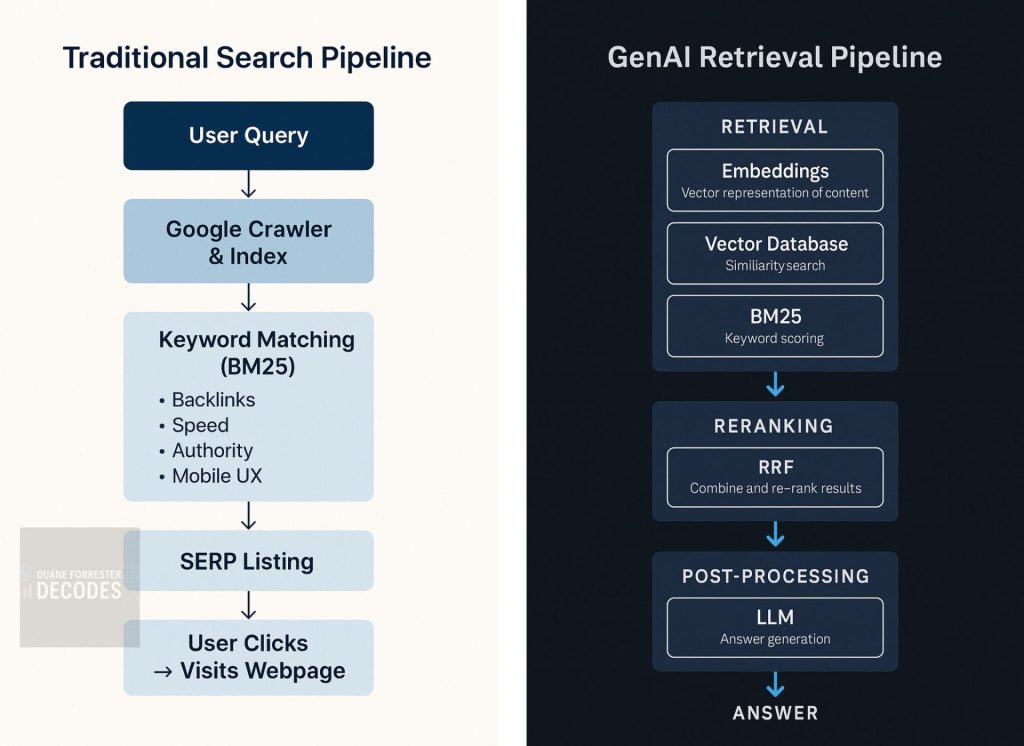
以下の図は、BM25とベクトル類似度を使ったランキング動作を比較した概念図です。
2つのシステムがどのように「関連性」を判断するかを、架空のデータに基づいて示しています。
それぞれのドキュメントは、意味や一致度に応じて順序付けられていることにご注目ください。
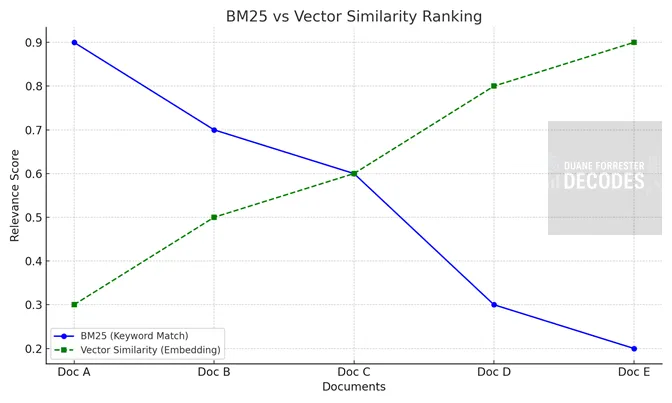
RRF(Reciprocal Rank Fusion)は、BM25やベクトル類似度といった複数のランキング手法を、ひとつのランキングリストに統合することを可能にします。これによりBM25による、キーワードヒットとベクトル類似度による意味的マッチのバランスがとれ、最終的な検索結果が、いずれか一方の検索方式に偏ることがありません。
RRFでは、BM25とベクトル類似度によるランキングシグナルを、「逆順位スコア式(Reciprocal Rank Score:RPF式)」を用いて統合します。
以下のグラフでは、それぞれ異なる検索システムにおいて文書がどのような順位にあるかが、最終的なRRFスコアにどのように寄与するかを示しています。
たとえどちらの手法でも1位でなくとも、複数の検索アプローチで一貫して高く評価されている文書は、RRFにおいても高く評価されます。
このモデル化により、結果リストがより緻密に並べ替えられていることがわかります。
検索スタックが抽出した上位結果をもとに、LLMが要約、言い換え、あるいは原文を引用する形でこれらを組み合わせて回答を生成します。
ここがいわゆる「推論レイヤー(reasoning layer)」です。ここでは、コンテンツの出所よりも、「質問に答える役立ち度」が重視されます。
インデックス自体は依然として存在します。ただし、その姿は変わりました。
もはや、クローラーでページが巡回されて、インデックスされ、ランキングされるのを待つ必要はありません。
現在はコンテンツをベクトル化してベクトルデータベースに格納し、メタデータではなく意味ベースで検索できるようにします。
・社内のデータであれば、こうした処理は即時に行われます。
・公開Webコンテンツの場合は、GPTBotやGoogle-Extendedなどのクローラーが今もページを取得していますが、その目的は従来のSERP(検索結果)を作ることではなく、コンテンツの意味を把握し、インデックスするためです。
この新しいモデルは、従来の検索エンジンを置き換えるものではありません。
ただし、従来の検索では対応が難しかったタスクに対しては、飛躍的な進化をもたらします。
たとえば、
この製品スタックが優れている理由は以下の通りです。
このため、エンタープライズ検索、カスタマーサポート、社内ナレッジシステムといった分野では、すでにこの新しいスタックが採用されています。そして現在、一般的な検索領域でも、この方向へと大規模にシフトしつつあります。
ベクトル検索は強力ですが、あいまいな面もあります。意味的な近さは捉えられるものの、「誰が、何を、いつ」といった人間の世界で当然とされる関係性までは完全には表現できません。
そこで役立つのが、ナレッジグラフ(Knowledge Graph)です。
ナレッジグラフは、システムが曖昧さを解消し、推論できるようにするために、エンティティ(人・製品・ブランドなど)の関係性を定義します。たとえば、「Apple」と言ったとき、それは企業のことなのか、それとも果物のことなのか?「それ」とは物体のことか、それとも顧客のことか?
以下のように、それぞれが補完し合います。
つまり、ナレッジグラフと新しい検索スタックは二者択一ではありません。優れた生成AIシステムは、これらを組み合わせて活用します。
まず、私たちが馴染みのある「従来の検索において上位表示を狙う方法」をざっとおさらいしましょう。
重要なのは、ここで示すのは網羅的なリストではないという点です。これは、これから紹介する生成AI時代の戦術と比較するための背景です。従来の検索でさえ非常に複雑です(私は以前Bingの検索エンジンに関わっていたので、それはよく分かっています)。それでも、以下の内容を見れば、生成AI向けの対策がむしろシンプルに思えるかもしれません。
従来型検索での上位表示には、以下のような要素が重要でした。
さらに、以下も加えると、より成果が期待できます。
これは、技術的な土台、コンテンツの関連性、そして評判を組み合わせたものであり、他サイトがあなたをどう扱うかによって評価されます。
ChatGPT、Gemini、CoPilot、Claude、Perplexity などの生成AIに、自社のコンテンツを参照してもらうにはどうすればよいのか?以下は、すべてのコンテンツ提供者が取るべき具体的な戦術です。
1. チャンク化と意味検索を意識した構造づくり
コンテンツを取得しやすいブロックに分割しましょう。
<h2> や <section> などのセマンティックHTMLを使ってセクションを明確に分け、アイデアを整理します。FAQ形式やモジュール型の構造も有効です。
これが、LLMが最初に読む「レイアウト層」になります。
2. 巧妙さより明快さを優先する
賞賛される文章よりも、理解される文章を目指しましょう。
専門用語・比喩・曖昧な導入文は避け、ユーザーの質問に合わせた、具体的でわかりやすい回答を重視します。
これにより、意味的なマッチング精度が向上します。
3. AIにクロールされる環境を整える
GPTBot、Google-Extended、CCBot などのクローラーがサイトにアクセスできなければ、サイトは存在しないも同然です。
JavaScriptでレンダリングされるコンテンツは避け、重要な情報は生のHTMLで提供しましょう。
また、schema.orgのタグ(例:FAQPage、Article、HowTo)を使って、クローラーにコンテンツの種類を明示します。
4. 信頼と権威のシグナルを整える
LLMは、信頼できる情報源を好みます。
署名、公開・掲載日、連絡先、外部引用、著者プロフィールなどの要素を明示することで、生成AIの回答に表示される可能性が高まります。
5. ナレッジグラフのように社内コンテンツを構造化する
関連するページを相互にリンクさせ、サイト全体の構造的なつながりを定義します。
ハブ&スポーク構造や用語集、コンテキストリンクなどを使って、意味的な一貫性を高めましょう。
6. トピックを深堀りし、モジュール式に構成する
単に主要な質問に答えるのではなく、あらゆる角度から情報を提供します。
コンテンツを「何」「なぜ」「どうやって」「比較」「いつ」といった形式で分けたり、冒頭要約(TL;DR※TL;DR=Too Long; Didn’t Read)やサマリー、チェックリスト、表などを追加するのが効果的です。
こうした工夫により、コンテンツは要約や再構成に適した汎用性の高い形になります。
7. 表現の確信度を高める
LLMは、記述の確信度も評価します。
「〜かもしれない」「〜と思われる」といった曖昧な表現は避け、明確で断定的な言葉を使いましょう。
自信のある記述は、表示される可能性が高くなります。
8. 言い換えを重ねて表現の幅を広げる
同じことを別の言い回しで繰り返しましょう。
表現のバリエーションを増やすことで、さまざまな検索クエリにヒットする「受け皿」を広げられます。
検索エンジンは意味でマッチしますが、言い回しを複数用意しておくとベクトル空間に残る“足跡(vector footprint)”が増え、その足跡によって検索クエリとの距離が縮まります。そして検索漏れを防ぎ検索再現率を高めることができます。
9. 埋め込み可能な段落を作成する
ひとつの段落には、ひとつの明確なアイデアだけを含めましょう。
複数の話題を混ぜず、シンプルな文構造を用いることで、コンテンツの埋め込み・取得・統合が容易になります。
10. 潜在的なエンティティに文脈を与える
明白に思える情報でも、はっきりと言語化しましょう。
たとえば「最新モデル」ではなく、「OpenAIのGPT-4モデル」と明記します。
エンティティ参照が明確であればあるほど、ナレッジグラフや曖昧性解消の精度が高まります。
11. 主張の近くにコンテキストを配置する
主なポイントから離れすぎずに、それを裏付ける情報(例・統計・比喩など)を配置します。
これにより、チャンク単位での一貫性が高まり、LLMが内容を確信を持って処理できます。
12. 構造化された抜粋を生成AI向けに提供する
AIクローラーがコピーしやすい、クリアな情報を用意しましょう。
箇条書き、回答の要約、「要点」セクションなどを活用し、情報の価値を際立たせます。
これはPerplexityやYou.comなど、スニペット形式の生成AIに有効です。
13. ベクトル空間に関連コンテンツを密集させる
用語集、定義、比較記事、事例などの周辺コンテンツを公開し、互いにリンクさせましょう。
トピックを密にクラスター化することで、ベクトル検索でのリコール率が上がり、主要コンテンツの可視性も高まります。
成果を確認したいときは、コンテンツで取り上げた質問を、PerplexityやChatGPTのブラウジングモードで聞いてみましょう。
もし表示されないなら、構成と表現を見直し、明確さを高めたうえで再挑戦してください。
あなたのウェブサイトは、もはや目的地ではありません。
それは、生成AIが回答をつくるための「原材料」なのです。
今後は、引用・参照・要約され、誰かが読んだり聞いたりする回答の一部として使われることが期待されます。
この傾向は、MetaのRay-Banスマートグラスのような新しい消費チャネルが増えるほど、ますます強くなります。
ページ自体の存在は依然として重要ですが、それはあくまで「足場」にすぎません。
勝ちたいなら、ランキングだけにこだわるのをやめ、情報源としての価値を高めましょう。もはや「訪問されるか」ではなく、「引用されるか」がカギです。
※本記事はもともと、Substack『Duane Forrester Decodes』にて “Search Without a Webpage(ウェブページなしの検索)” というタイトルで公開されたもので、許可を得て再掲載されています。
SEO Japan編集部より:先日話題になったiPullRank社のMike King氏の記事と同様に、「クリック外の可視性」をKPIにする方向を提唱しており、いずれも「機械が読む単位」で情報設計する必要を説いています。
一方で、当記事では短期タスクを中心に「今すぐできるTodoリスト」を示しており、ここで紹介されていることに取り組みつつ(llms.txtは懐疑的ですが)、今後の大きな方針としては、次のゲーム盤そのものを解説しているiPullrank記事を基に、組織とデータ基盤の再設計を検討すると良いかもしれません。AI Modeの対応について、わかりやすくかみ砕いた当社遠藤のブログ記事も併せてご確認ください。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










