![]()

![]()

SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
この記事は、2025年 5月 8日に ipullrank で公開された Francine Monahan氏の「An Introduction to Relevance Engineering: The Future of Search」を翻訳したものです。

検索の次なるステージでは、「どんな種類の検索結果にも自然に表示される、関連性の高いコンテンツ」を“設計(エンジニアリング)”することが求められます。
企業は、生成AIをはじめ、TikTok、Amazon、さらにはアプリストアまで、あらゆるチャネルでの“見つけられやすさ=可視性”を確保しなければなりません。
それぞれのチャネルには固有の特徴がありますが、すべてに共通するのが「関連性(Relevance)」です。
レリバンスエンジニアリング(検索エンジンやAIにおける可視性を“エンジニアリング=設計課題”として扱う手法)は、現代の検索とAIシステムでの可視性を「最適化」という枠組みではなく、エンジニアリングの問題として扱います。
「最適化」ではなく「エンジニアリング」という考え方が適しているのは、何かを調整するよりも、何かを構築しなければならないことが多いからです。それがソフトウェア、コンテンツ、またはインターネット全体での関係であっても、すべてエンジニアリングの一形態として捉えるべきなのです。
AI OverviewsからYouTubeのアルゴリズムまで、ほぼすべてのオーガニック検索システムは、視聴時間、滞在時間、離脱率などの行動シグナルに依然として大きく依存しています。しかし、検索結果として表示されるものは変化しています。検索エンジンは今やクエリ(検索語句)をセマンティック(意味的)に展開し、トピッククラスターを活用しています。それでもSEO業界は、時代遅れのフレームワークに戦略を無理やり当てはめ続けています。
ほぼすべての検索が今や生成AIを使用しているため、このエンジニアリングプロセスはどこでも機能します。
例えば、YouTubeに関しては、動画内の画像や動画で話されている内容の最適化は、依然としてユーザーインタラクション(視聴時間、離脱率など)に大きく依存しています。これはオーガニック検索の仕組みでもありますが、標準的なSEO作業だけでは十分ではありません。
従来型のSEOは、もはや実際には機能しない、また検索エンジンが現在使用していないフレームワークに、すべてを当てはめ、押し込もうとし続けています。
これまでの自然検索では、ページ上の特定のキーワードを探して検索結果ページでのランクを決定するため、一部の無関係なコンテンツが高いエンゲージメントを獲得し、良いパフォーマンスを示すことがあります。一方AIは関連性のあるソースから特定の文章やフレーズを探します。そして、それらを見つけるためにサイトの深くまで入り込みます。実際、Google AI Overviewsの引用の82%は深いページから来ています。
これは何を意味するのでしょうか?私たちはもはや単にコンテンツを最適化するだけではいけません。エンジニアリングする必要があるのです。
目次
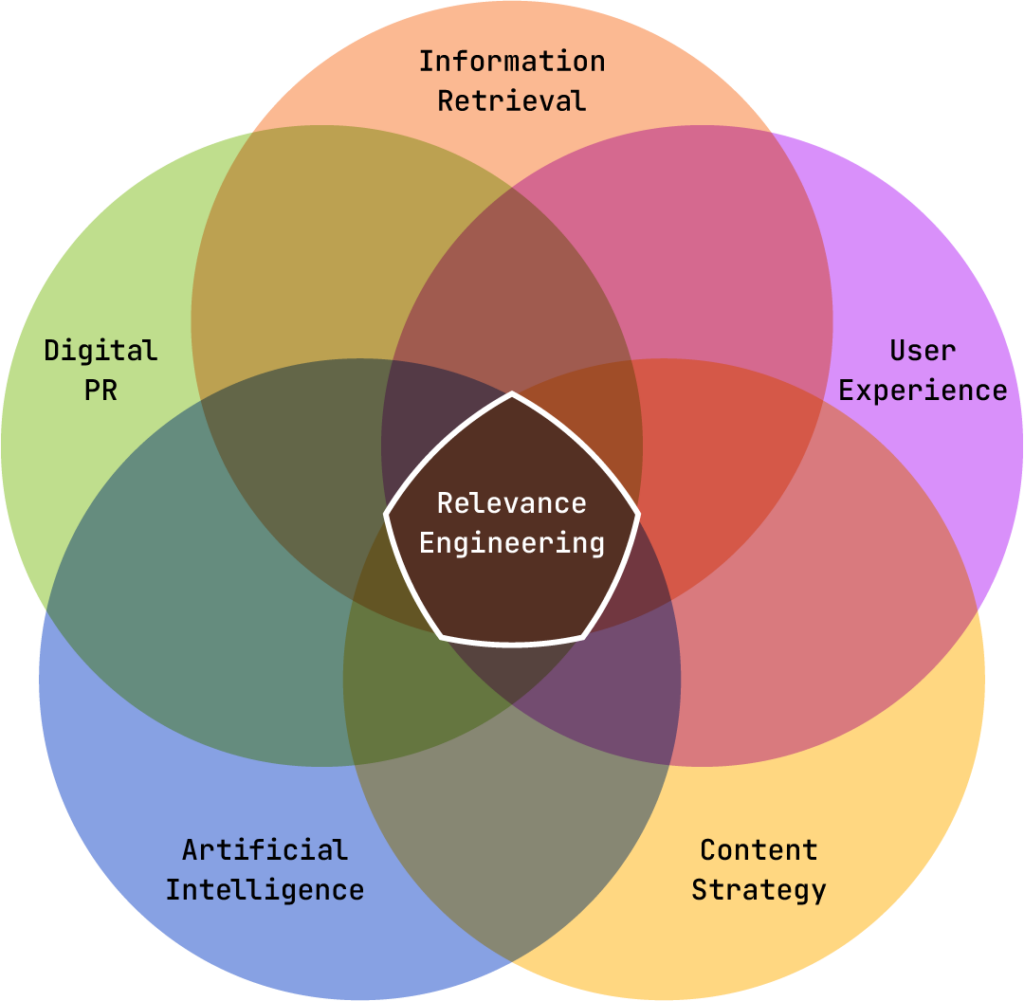
レリバンスエンジニアリングとは、あらゆる検索環境での“可視性”を高めるための、技術と理論の融合です。
情報検索(Information Retrieval:大量の情報の中から関連するものを探す技術)、ユーザー体験(UX)、人工知能(AI)、コンテンツ戦略、デジタルPR(広報活動)の交差点にあるこの考え方は、検索のあらゆる局面において役立ちます。
言い換えれば、これは会社のブランドを構築し、顧客や見込み客のために役立つコンテンツを作成し、わかりやすく、アクセスしやすく、検索者がリピートしたくなるようなサイトを設計するという、長年にわたるSEO担当者のすべての努力の集大成なのです。
これまで私たちが「良きWebサイト」を作るためにやってきた事の延長線上に、レリバンスエンジニアリングはあります。
生成AIを活用した検索(AI Overviews、Perplexity、Geminiなど)の登場により、検索は今や「クリック不要の回答セットをその場で提供する」形に進化しています(これを“強化版スニペット”と呼ぶ人もいます)。
これはSEOの日常的な仕事と生活にどのような影響を与えるのでしょうか?典型的な過去のSEO思考を変える必要があります。ページタイトルやH1タグでキーワードを使用し、常により多くのリンクを構築するといった要素は、生成AI環境では重要ではありません。あなたが実際に行っていることが針を動かすかどうかを検証するために、より技術的な理解が必要です。
レリバンスエンジニアリングは、関連性を定量的で測定可能なものに変えます。
SEOはしばしば曖昧な情報や、Google検索の仕組みについて研究している誰かの意見を参考に実施されますが、レリバンスエンジニアリングは、検索へのより科学的なアプローチ方法です。
しかし、レリバンス(関連性)は主観的ではないため、私たちのツールにはレリバンススコア(関連性を測る指標)が必要です。
会話型検索(Conversational Search)は主に関連性を重視し、数学的にスコア付けできます。
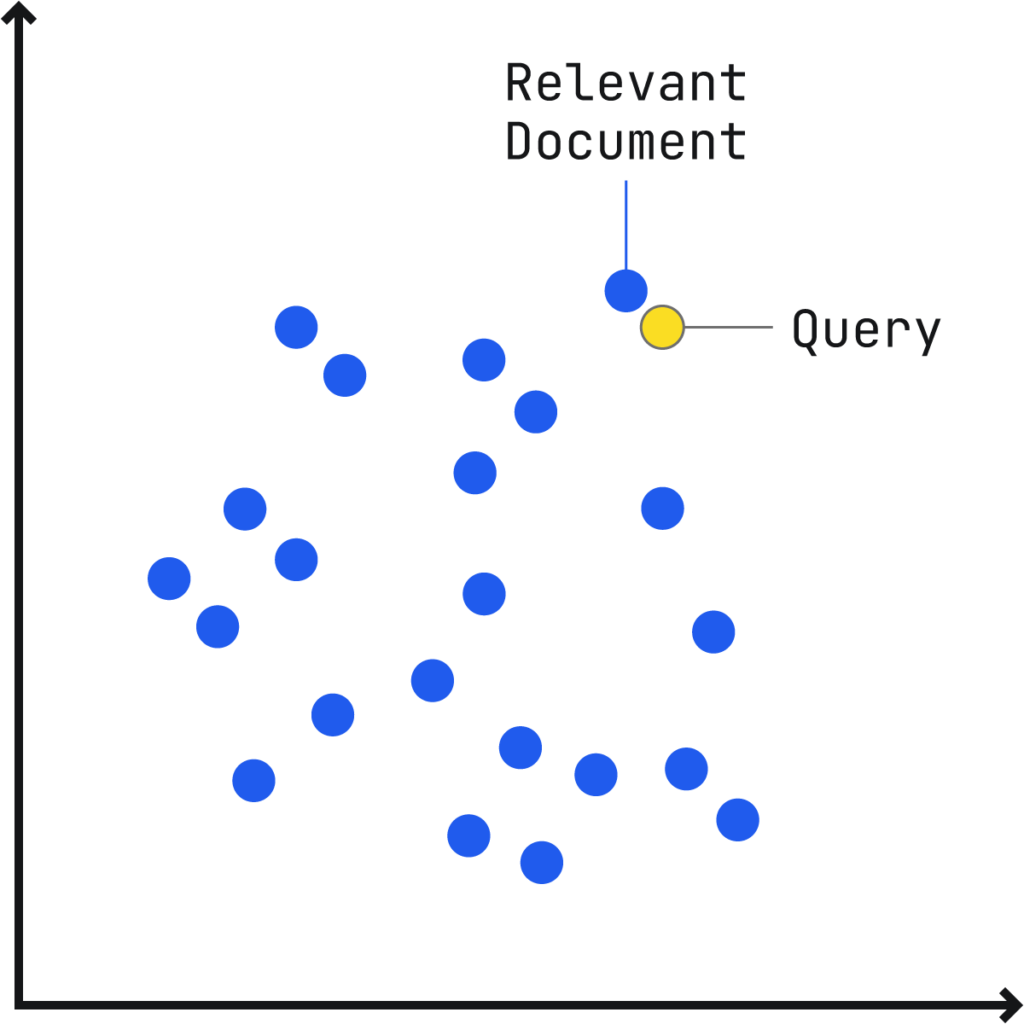
従来の検索と同様に、検索クエリと関連する文章のつながり(文書)を「多次元ベクトル空間(Multidimensional Vector Space)※」にプロット(配置)し、文書ベクトルがクエリベクトルに近いほど、関連性が高くなります。
※SEOJapan補足:「多次元ベクトル空間」
検索語と文章の内容をそれぞれ「地図の上の点」のように配置し、その距離の近さで関連度を測る仕組みのこと(これを“ベクトル空間”と呼びます)。「意味が似ているほど近くに置かれる」ことで、AIが「この文章はこの質問にピッタリだ」と判断できる。
HubSpotが2005年に「インバウンドマーケティング」という言葉を作ったとき、彼らは孤立して機能すると考えられることが多いチャネル(ブログ、SNS,メールなど)を常に連携させるべきであると提唱しました。
同じように、私たちも「レリバンスエンジニアリング(関連性設計)」という新しい枠組みを提示し、それに取り組む人々は、複数の専門分野にまたがってスキルを高めていくことが求められています。
これまでのSEOの専門家たちは、ベストプラクティスには詳しく、検索エンジンの「熟練ユーザー」ではありました。しかし、現在の「SEO」という言葉は非常にあいまいで、Googleが新しく発表した技術や概念は、すべて自動的に「SEOの仕事」に分類されてしまう傾向があります。
そのため、レリバンスエンジニアリングは、従来のSEOを超えて、情報検索・UX・AI・コンテンツ戦略・デジタルPRなど複数の領域を横断した新しいフレームワークとして位置づけられるのです。
また、レリバンスエンジニアリングは、コンテンツをマーケティング戦術ではなく科学的システムの一部として扱い、品質をその中核的方法論に組み込みます。
SEO業界で多くの人が「コンテンツ戦略」と呼ぶものは、実際には理論上だけで組み立てられ、実務には落とし込まれない複雑な計画にとどまることがしばしば見受けられます。
これに対して、レリバンスエンジニアリングは、すべての作業が明確な目的のもとに機能するようなワークフローを取り入れています。そして、これまで行き当たりばったりで進められてきたプロセスに、工学的な規律と科学的な厳密さをもたらすのです。
具体的には:
レリバンスエンジニアリングは、コンテンツの可視性を高めるための、構造的かつAIを活用した新たなアプローチです。前述のとおり、この手法は【ユーザーエクスペリエンス】、【人工知能(AI)】、【コンテンツ戦略】、【デジタルPR】、【SEO】、そして場合によっては【オーディエンス調査】といった複数の分野を統合し、ユーザーの期待と検索エンジンの評価基準の両方に沿ったコンテンツを設計していきます。
なお、オーディエンス調査がすべての最適化に必須というわけではありませんが、多くのSEO実務者が軽視しがちな非常に重要な要素です。なぜなら、ユーザーの意図を正確に理解することが、真の意味での「関連性(レリバンス)」を実現する上で不可欠だからです。
Googleが重視しているEEAT(Experience, Expertise, Authoritativeness, Trustworthiness:経験・専門性・権威性・信頼性)の観点からも、レリバンスエンジニアリングの手法は、単なるキーワードマッチングを超えた次元へと進化しています。Googleは、ベクトル埋め込み(vector embeddings)と呼ばれる技術を用いて、著者・ウェブサイト・エンティティ(≒明確に識別可能な情報の単位)などのレベルで評価指標を測定し、各ページがユーザーの期待にどの程度応えているかを数値的に判断しています。
たとえば、スニーカーに特化したサイトが、突然バナナに関するコンテンツを掲載し始めた場合、サイトのテーマに一貫性がなくなり、それは「フォーカスの薄さ」として認識され、検索エンジンから「無関係な情報源」とみなされるおそれがあります。同様に、戦略の裏付けもないままAI生成コンテンツに過度に依存すると、Googleのアルゴリズムからネガティブな評価を受ける可能性があります。
ここで誤解してはならないのは、EEATが単に「著者の経歴」を評価する仕組みではないということです。実際、Googleはウェブ上に存在する著者の情報をモデル化し、各著者に対してベクトルを作成。それを使って、他の著者と相対的に比較しようとしています。
さらに、Googleはウェブサイト単位でもベクトルを生成します。これは、サイト内の各ページをベクトル化し、それらを平均してサイト全体のベクトルを導き出すという方法です。著者に対しても同じ処理が行われ、彼らが書いた全コンテンツを収集し、そのアウトプット全体をベクトル平均で表現するのです。
もちろん、著者紹介ページそのものが無価値というわけではありません。特定の人物として他の執筆者と差別化を図るうえでは、有効に働きます。しかし、本質的な価値は「特定のトピックについて十分な量のコンテンツを書いているかどうか」にあります。たとえば100本の記事のうち60本がSEOについて書かれていれば、数学的に見てその著者は「SEOの専門家」と分類されるわけです。
EEATという言葉は非常に抽象的であり、Googleが実際に行っていることの全体像を表している一方で、SEO業界ではこの概念の理解が単純化されすぎており、かえって誤解の温床になっています。もともとSEOは、技術的な仕組みを理解するウェブマスターや開発者たちの領域でしたが、最近ではテクニカルSEOやリンクビルディング、コンテンツSEOといった細分化された専門分野が生まれた結果、検索エンジンの仕組みを包括的に理解していない人が増えています。こうした分断は、レリバンスエンジニアリングの領域では起こりません。
レリバンスエンジニアリングでは、AIによる分析を活用し、コンテンツ戦略を実行する前の段階で、その施策が成功するかどうかを予測します。これは、Googleが内部で関連性を評価するために使用している可能性のあるロジックに似ており、公開されているツールを通じて実用的にも活用可能です。
たとえば、ターゲットトピックとのコサイン類似度(cosine similarity)※が低いコンテンツを公開したり、トピック的に整合性のないサイトからの被リンクを追求したりするようなことは、もはや行わないでしょう。このようなデータ主導型のアプローチは、これまでのSEOが依存してきた“推測”や“経験則”を最小限にとどめ、マーケターがより精密に、そして確実に成果を得られるよう最適化を進めていくための道を開きます。
※SEOJapan補足:「コサイン類似度」
「コサイン類似度」とは、「2つのベクトルがどの程度同じ方向を向いているか」を角度で測る指標のこと。自然言語処理の分野では、単語や文章の意味の近さを数値化する際に用いられる。
ドイツの研究者たちが、1年にわたるGoogle検索の縦断的調査を行った結果、アフィリエイトマーケティングを主目的としたSEOコンテンツが検索体験を悪化させているという実態が明らかになりました。
この種のコンテンツは、ユーザーの役に立つかどうかよりも、お金を稼げるかどうか(マネタイズ)を優先して作られているのが特徴です。研究によれば、現在の検索結果の多くは、ユーザーにとって本当に有益かどうかよりも、検索順位を上げることだけを目的に作られた商業的に最適化されたコンテンツに占められているとのことです。
Googleとしては、高品質で関連性のあるコンテンツと、単にトラフィックを集めるだけのページを見分ける必要があります。
Googleは「人間のために作られたAI生成コンテンツなら問題ない」と公言していますが、実際には“良いAIコンテンツ”と“悪いAIコンテンツ”を大量に区別することが非常に難しいという課題があります。従来型のランキングシグナル(被リンクなど)も依然として使われていますが、「ユーザーが検索体験を成功と感じたかどうか」などの行動指標が、品質を評価するうえでますます重要になってきています。
とはいえ、GoogleがAI生成コンテンツを検出する試みは、まだまだ信頼性に欠けています。たとえばOpenAIは、かつて提供していたAIテキスト検出ツールをわずか25%の精度しかなかったために撤廃しました。他の類似ツールも、本物の文章をAIと誤判定したり、AI文書を見逃したりするといった誤検出が頻発しています。
この不確かさのせいで、実際には学生のレポートがAI検出ツールにかけられて「AIが書いたもの」と誤って判断されてしまう事例も起きています。AIによるコンテンツ生成の検出は今も大きな課題であり、モデルが進化するスピードに対して、検出手法はすぐに陳腐化してしまいます。
こうした問題に対応するには、GoogleはAI検出のみに頼るのではなく、もっと多層的で頑健な評価手法に進化させていく必要があります。検索品質を維持するには、低品質なコンテンツを正しくフィルターし、ユーザーのニーズに合ったコンテンツを正確に見極めることが求められています。
その一環としてGoogleは、検索品質評価ガイドラインを更新し、スパムの定義を拡大しました。これにより、いわゆる「低品質コンテンツ」や、誤解を招いたり誇張された主張を含むページに対しても、価値の低いコンテンツとして対応できるようになりました。
検索エンジンがAIや機械学習への依存を強める中で、構造化データの役割はこれまで以上に重要になっています。構造化データは、検索エンジンが情報を理解・分類・関連付けしやすくするための仕組みであり、コンテンツをユーザーにとってよりアクセスしやすく、関連性のあるものにする手助けをします。
データを機械が読み取れる形式で整理することで、企業は検索結果や音声検索、さらにはAIによって強化されたあらゆる体験において、自社の可視性を高めることができます。
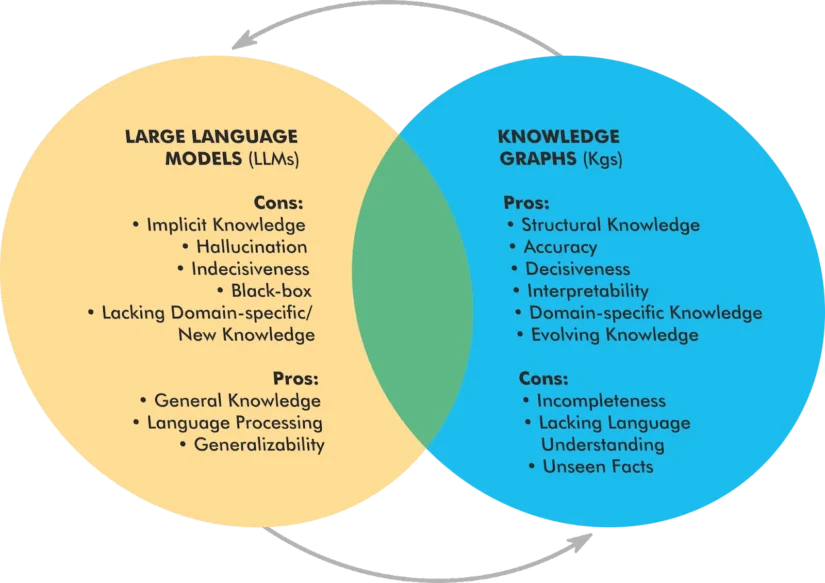
最近の技術進展により、構造化データはAIと並行して進化していることが明らかになってきました。特に、ナレッジグラフ(Knowledge Graph)※と大規模言語モデル(Large Language Models:LLM)を統合する以下の3つの新しいモデルの登場が注目されています。
※SEOJapan補足:「SEOにおけるナレッジグラフ」
SEOにおける「ナレッジグラフ」とは、Googleなどの検索エンジンがウェブ上の情報を「人・場所・物事」などの“実体(エンティティ)”として整理・理解し、それらの関係性を構造化してデータベース化したものを指します。
参考:ナレッジグラフとは?3分で分かるナレッジグラフ講座
この多層構造のシステムでは、LLMとナレッジグラフが動的に連携しながら、それぞれの強みを活かして知識の検索精度や推論力を高めていきます。
このように、構造化データを活用することは、検索可視性の向上だけでなく、AI主導の検索環境におけるコンテンツの将来性を保証することにもつながります。Googleの検索アルゴリズムが今後さらにLLMを取り入れていく中で、構造化データはコンテンツを正確に解釈し、文脈的に適切に処理するための鍵となるでしょう。
構造化データの活用により、企業は従来の検索における可視性向上だけでなく、AIを活用した新しい検索環境においても競争力のあるコンテンツを提供し続けることが可能になります。Googleの検索アルゴリズムが今後ますますLLMとの統合を進めていく中で、構造化データは、コンテンツを正しく解釈し、文脈的に関連性があることを保証する上で、さらに重要な役割を果たすようになるでしょう。
自社ブランドのコンテンツをより目立たせ、AIと対立するのではなく協調して機能させるためには、他にもさまざまな工夫があります。
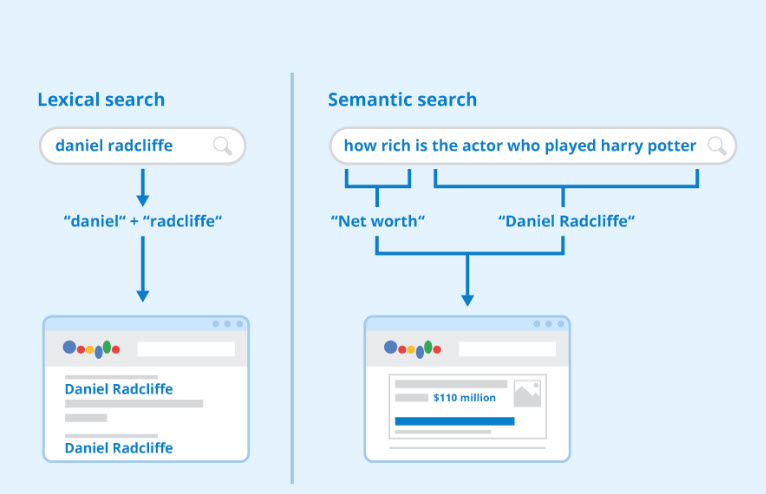
Googleは約10年前、ハミングバード(Hummingbird)アップデートによって検索エンジンの仕組みを「語彙的検索(lexical search)」から「意味的検索(semantic search)」へと転換しました。しかし、それ以降の多くのSEOソフトウェアはこの変化に追いついていません。
語彙的検索とは、単語の出現や分布をカウントするモデルです。一方で意味的検索は、言葉の「意味」を捉えることを重視しています。この意味的検索の基盤となったのが、Word2Vec(単語の意味をベクトルで表現する手法)です。
語彙的検索対セマンティック検索
AI Overviews(GoogleなどのAIが生成する検索結果の要約)に表示されるための鍵となるのが、フラグル(fraggles)と呼ばれる要素です。フラグルとは、AI Overviewsを構成する断片的な文章のことを指します。
たとえば、検索結果(SERP)内のAI Overviewsには、Webサイトから切り出されたフレーズ(フラグル)が使われています。
あなたのWebサイト上のコンテンツが、特定の質問に対するシンプルで分かりやすいフレーズとして整理されている場合、それがAI Overviewsに採用される可能性が高まります。
AI検索において表示される可能性を高めるために、以下のようにコンテンツを構造化することが効果的です。
内容を明確に定義されたトピックごとに、簡潔な段落やセクションに分けましょう。長すぎる段落は複数のアイデアを混在させ、ベクトル化された意味が曖昧になります。通常、50〜150語程度の短い段落が、意味的に明確なアイデアを捉えやすくなります。また、見出しや小見出しを使ってセクションを区切ることも重要です。
埋め込みモデル(embedding model)は、コンテンツ内に明示された関係性をもとに意味を捉えるため、こうした文構造は検索精度や関連性の向上に効果的です。
関連するキーワードや同義語、実在のエンティティ(固有名詞・概念など)を積極的に明示しましょう。これにより、検索でのヒット率や引用される可能性が高まります。
オリジナルのデータや独自視点の情報は、あなたのページが信頼性の高い情報源として引用される可能性を高めます。
はっきりとしたシンプルな文章は、ノイズを減らし、検索精度の向上に繋がります。
検索技術が進化する中で、レリバンスエンジニアリングは、コンテンツがユーザーの意図と検索エンジンの評価基準の両方に合致することを保証するために不可欠なアプローチとなっています。
EEATの重視、AIによるコンテンツ生成、構造化データの普及といった潮流は、推測に頼るSEOから、科学的かつデータに基づいたSEOへと移行する必要性を示しています。
一方で、検索品質の低下に対する懸念も残っています。たとえば、SEO主導のアフィリエイトコンテンツの増加や、AIによる「ハルシネーション情報」、そしてAI生成コンテンツの検出の難しさといった問題です。
Googleは、こうした課題に対応するために、従来のランキングシグナルに加え、ユーザーのエンゲージメント(検索体験が成功したかどうか)や構造化された知識に基づいて、より高度な評価指標を導入しつつあります。
SEOJapan編集部より:Webサイトをより良いものにするために、目指すべきゴールや本質はこれまでと変わっていません。その過程として意識すべきものが「レリバンスエンジニアリング」として、言語化されたと捉えられます。また、再現性の高いフレームワークが出来上がるということは、この先にコモディティ化が待っているということでもあります。
AI時代において、我々SEO担当者は新しいフレームワークに適応し、実践する能力が求められます。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










