![]()

![]()
ホリデーシーズンがやって来た今、私達は皆、自身を元気づける必要があるかもしれない。そこで私は、私達のお気に入りの検索エンジン、Google、Yahoo、Bing、YouTube、Blekkoで楽しもうと考えた。
Nine By Blueでは、サイトの技術的なSEOのベストプラクティスを自動的にチェックするソフトウェアを開発してきた。通常は、自分達のクライアントサイト上で、問題がないか素早くチェックしたり、今後の問題をモニターするためにそれを実行する。
しかし、私は、このソフトウェアを検索エンジンサイト上の代表的なページに合わせて、彼らの実装と通常私達が推奨する技術的なSEOのベストプラクティスを比較してみたらどうなるだろうと興味を持った。
以下は私が見つけたいくつかの問題をリスト化したものだ。順番は特に意味はない。
免責条項その1: このリストは、SEOのためにサイトを完全に最適化するのがいかに難しいか(特に大規模な企業サイトでは)を指摘することを目的としている。私は、もし自分がこれらのサイトを思い通りに管理できるならもっとよくできたと主張したいわけではない。
免責条項その2: うん、GoogleのSEOレポートカードは知っているが、あまりにも長すぎるので読んだことは一度もない。それに、私はそれに影響されたくなかったのだ。
目次
私が調査したサイトのほとんどが、ホームページへと誘導するたくさんの異なるURLを持っていた。これには、トラッキングパラメータ(例 https://www.site.com/?ref=affilliate1)や、デフォルトファイル名(例 https://www.site.com/index.php)、そして、重複するサブドメイン(https://www1.site.com/)さえも原因となる。
このため、私はいつも、ホームページ上にlink rel=canonicalタグを置くことを推奨している。これが、これらの異なるホームページURLへのリンクが同じURLを指しているようにカウントされることを保証する。さらに、同じような問題の可能性がある他のページにもこのタグを追加することを推奨する。
適切なlink rel=canonicalタグをホームページ上に持っていたサイトがBingだけだと判明し、私は驚いた。
YouTubeにもlink rel=canonicalタグがあるが、それは完全なURLhttps://www.youtube.com/ではなく、不適切なURL“/”を指していたのだ。
いくつか例外はあるが、私は調査したサイトの重複コピーを見つけることができた。
私は、一般的にはそのサイトのコピーであることが分かっている典型的なサブドメイン―www1、dev、api、mなど―のリストを持っている。サイトの他の重複するコピーは、IPアドレス(例 https://www.site.com/の代わりのhttps://192.168.1.1/)にあったり、追加のホスト名やドメインのための厳密なDNSによって見られる。
これらの重複するサブドメインや重複サイトはSEOにマイナスの影響を及ぼす。それらが検索エンジンに1つのコピーを獲得するのにあなたのサイトの複数のコピーをクロールさせるからだ。それはさらに、特定のページに向けたリンクが複数のコピーの間に広まって、そのページのオーソリティを減少させる原因にもなる。
これを修正する一番良い方法は、そのURLのカノニカルサブドメインのバージョンに対してパーマネント(301)リダイレクトを使用することだ。それが不可能なら、カノニカルサブドメインページを指しているlink rel=canonicalタグがほぼ同じような働きをするだろう。
例えば、Bing.comの重複コピーはhttps://www1.bing.com/で利用可能になっている。これを悪化させるのが、そのページにはhttps://www1.bing.com/を指し示すlink rel=canonicalタグがあり、ページ上の全てのリンクが同様にwww1を指示しているという事実だ。
www2からwww5、そしてwww01のようなその他のサブドメインは、301を使用して全て適切にwww.bing.comへリダイレクトしている。
Blekkoの場合は、https://api.blekko.com/にサイトの古いローンチ前のコピーがある。(これは彼らの昔の幹部ページだ)幸運にも、このサブドメインには、それがクロールされないようにしているrobots.textファイルがある。しかし、https://api.blekko.com/mgmt.htmlにある古い幹部ページをはじめとするこれらのページは、https://dev.blekko.com/mgmt.htmlや、メインサブドメインのhttps://blekko.com/mgmt.htmlでも利用可能なのだ。
異なるサブドメイン上に複数のコピーを残しておくよりも、これらのURLを現在のマネジメントページhttps://blekko.com/ws/+/managementに301リダイレクトした方が良い。
YouTubeは、重複するサブドメインwww1~www5をwww.youtube.comにリダイレクトしており、ベストプラクティスと一致している。残念ながら、それは推奨される301(パーマネント)リダイレクトではなく302(テンポラリ)を使ってリダイレクトしている。
私がよく発見するサイトの重複コピーのもう1つのタイプは、サイトのSSL/httpsバージョンだ。httpsは、ログインページやユーザープロフィールを編集するページのようにセキュリティを必要とするページに適しているが、セキュリティを必要としないページにとっては、それは非能率なクロールとリンク拡散を引き起こす複製コンテンツのもとになる。
これに対するお勧めのソリューションは、可能な時にはいつでもhttpsからhttpにページをリダイレクトすることだ。
私達のソフトウェアは、Microsoftのヘルプページや、YouTubeのaboutページ、Googleの企業ページ、そして、Googleウェブマスターガイドラインを含む大部分のページの重複するhttpsコピーを検知した。
Googleウェブマスターガイドラインページ(およびその他のGoogleヘルプページ)にある複製コンテンツ問題は、URLの要求によってhttpもしくはそのURLのhttpsバージョンを指し示すlink rel=canonicalタグによって悪化する。
必ずlink rel=canonicalタグが常にページのカノニカルバージョンを指示しているようにすることが大切であるため、この要素を動的に生成するときには注意することだ。
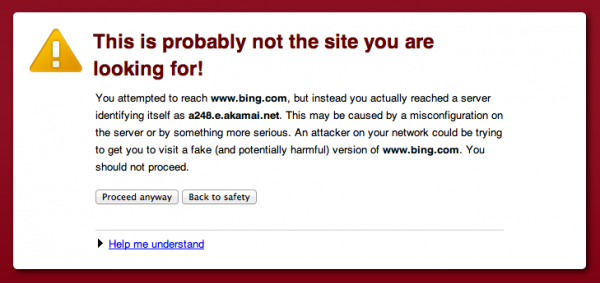
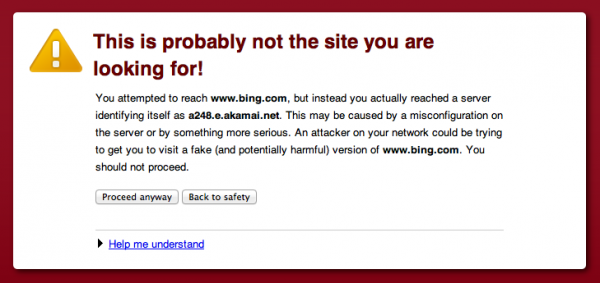
https://www.bing.com/へのリクエストは、SSL証明書の不一致が原因で、セキュリティ警告をもたらしている。これはグローバルサーバーロードバランシングにAkamaiを使用しているサイトによくあることだ。
それは、https://www.whitehouse.gov/でも表示される。私はこの問題を回避する方法が分からない。これについてはAkamaiの誰かと話をしたいものだ。
一般的にサイトは、検索エンジンにインデックスして欲しくない様々な種類のページを持っている。これは、これらのページがコンバートしそうにないか、“アカウント作成”や“コメント投稿”ページのようにユーザーにとって良い体験ではないのが理由かもしれない。もしくは、そのページがAPIのコールに対するXMLのレスポンスのように、Webブラウザ向けではないのが理由かもしれない。
https://api.bing.com/ やhttps://api.bing.net/で始まるURLを作るBingの検索APIのコールは、robots.txtファイルに準じてスパイダーにクロールされ得る。これが、効率的なクロールに計り知れない影響を与えるのだ。なぜなら、検索エンジンは、たとえブラウザにとって役に立たないとしても、これらのXMLの結果をクロールし続けるからだ。
Googleで[site:api.bing.net OR site:api.bing.com]を検索すると、現在およそ260件の結果を返すが、私がクライアントのWebアクセスログで行った分析に基づくと、これよりも何倍も多いURLがクロールされ拒否されてきたのだ。
画像には常にALT属性を介して(私がいくつかのサイトで目にしてきたTITLEやNAMEではなく)代替テキストを入れるべきである。これは、スクリーンリーダーのようなアクセシビリティの問題に効果的だし、そのページに関する追加のコンテクストを検索エンジンに提供する。
チェックしたページ上の多くの画像には適切な代替テキストがあったが、私は、Duance Forresterのプロフィールページ上の彼の画像にはそれがなかったことに触れずにはいられなかった。しかし、彼は良い会社にいる。なぜなら、LarryもSergeyもEricも、その他のGoogleの幹部チームにもそれがないからだ。
リンク上のrel=nofollow属性は、検索エンジンにそのリンクをリンクグラフの一部として見ないように教えている。時々、私は、PageRankがサイトに“流れる”入口を制御するためにこの事実を利用しようとするサイトを批評する。
このテクニックは一般的には効果がなく実際には逆効果であると考えられており、私は常にそれを勧めていない。(robots.textによってクロールされることから除外されているページへのリンクのように、内部リンクにおけるrel=nofollow 属性の有効利用は未だに存在する。)
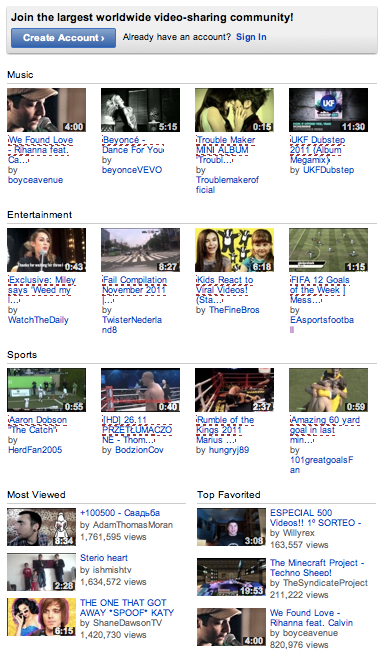
私がチェックした検索エンジンページでは、YouTubeのホームページを除き、この方法でrel=nofollow 属性を使用しているものはなかった。
以下の画像では、nofollowedリンクには赤線が引かれている。Most Viewed(視聴者数の多い動画)とTop Favorited(評価の高い動画)へのリンクは検索エンジンに示されるが、一般的な音楽、エンターテイメント、スポーツの動画は示されないのだ。
有効なページに誘導しないURLは404(Page Not Found)レスポンスコードを直接返すべきだ。
無効なURLがBingのコミュニティブログサイトに送られている場合、それは404ページにリダイレクトする。これがそのつながりだ:
推奨されるベストプラクティスは、最初のURLが404を直接返すことだ。もしそれが不可能なら、リダイレクトは301(パーマネント)に変更すべきだ。
Yahooの会社情報ページは、無効URLを取得した時に面白いことをする。
有効なURLではないhttps://info.yahoo.com/center/us/yahoo/anypage.htmlへのリクエストは、404(Page Not Found)レスポンスを正確に返す。
しかし、404ページには、1秒でhttps://info.yahoo.com/center/us/yahoo/へリダイレクトする時代遅れのメタリフレッシュが含まれているのだ。
このページへの301リダイレクトが、これらの無効URLに対処するには推奨される方法だ。
私は、効率的にクロールを増やしてページ速度を減少するキャッシュコントロール・ヘッダを使うのが大好きだ。(この件に関する私の記事はこちら。)
私がチェックした全てのURL中、ほんの少しのGoogleURLがIf-Modified-Sinceリクエストをサポートしていたが、If-None-MatchをサポートしていたURLが1つもなかったのは興味深いと思った。
私は、サイトレビューの一部として、DNSの構成をチェックするためにhttps://intodns.com/ や https://robtex.com/のようなオンラインリソースを使うのが好きだ。
DNSは技術的なSEOの重要な部分だ。なぜなら、もし何かがDNSを破れば、そのサイトはダウンし、クロールされなくなる。幸いにも、これはめったに起こらない。
しかしながら、私は、DNSの変更によってクロールに影響が及んだサイトをレビューしたことがある。また、同じサブネット上にDNSサーバーを持っていて、ビジネス全体に単一障害点を生み出していた大きなサイトをいくつかレビューしたことがある。
予想通り、全ての検索エンジンにおいて重大なDNSの問題はなかった。そのうち2つが、いくつかのレアな事例がセキュリティリスクになり得るとして、ネームサーバー上で再帰を有効にしていたことには驚いた。
私が推奨するベストプラクティスは、これらのチェックを少なくとも四半期に一度実行することだ。
ここに紹介したものは、私がよく目にし、重要だと思った問題だ。他にもあったが、それらは、短いタイトルやメタデスクリプションの複製や欠如、ヘッダの欠如、ページごとにあまりに多すぎる静的リソースなど、比較的大したことがないか微妙なことだった。
通常なら、私はWebアクセスログファイルへのアクセスを持っていて、私達のソフトウェアにもっと多くのことをチェックさせることができる。
これがあなたに自分自身のサイトでチェックすべきことに関して何らかのアイディアを提供することを願っている。そして、あなたには、時々検索エンジンさえも技術的なSEO問題を持っていることを認識して欲しい。
この記事に書かれた意見はゲスト投稿者のものであって、Search Engine Landのものとは限らない。
この記事は、Search Engine Landに掲載された「Do As I Say, Not As I Do: A Look At Search Engines & SEO Best Practices」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。










