![]()

![]()
![]()
SEOコンサルティングサービスのご案内
専門のコンサルタントが貴社サイトのご要望・課題整理から施策の立案を行い、検索エンジンからの流入数向上を支援いたします。
 無料ダウンロードする >>
無料ダウンロードする >>
SEO業界の関係者(または参入を望む人達)は、様々な細かい仕事に追われている。サーバーの構造、301 リダイレクト、404 エラー、タイトルタグ等々、数えれば切りがない。
そのため、じっくりと腰を落ち着け、それぞれの作業がどのような意味を持っているのか考えることを怠ってしまう。また、大半のSEOのスタッフは、一度もトレーニングを受けたことがなく、「その場」で何とかしなければならないため、検索エンジンの仕組みを知らないSEOのスタッフが多いのは致し方ないのかもしれない。
(グーグル等の)検索エンジンの仕組みを時間を割いて考えたのは、何年前のことだろうか?私は、先日のグーグルウェブマスターハングアウト、そして、このチャットで明らかになったリンク否認ツールの情報を記事(日本語)にまとめていた先月、久しぶりに検索エンジンの仕組みを真剣に考える機会を得た。
しかし、正直に言うと、否認ツールに関する記事を書くまで、8-10年間のブランクがあったと思う。そこで、この記事を通じて、悪習を断ち切っていく。この記事では、上級者に向けて、検索エンジン(グーグル)の仕組みを説明していく。用語や運用の順番は若干異なるかもしれないが、ビングとヤフー!も同じ様なプロトコルを利用している。
グーグルがサイトを「インデックス」した、とは何を意味するのだろうか?SEOの関係者は、グーグルで[site:www.site.com]検索して、サイトが提示されたと解釈する。これは、グーグルのデータベース内のページがデータベースに加えられたことを意味するものの、必ずしもクロールされているわけではなく、そのため、次のメッセージが時折表示されるのだ:
の結果の説明は、このサイトのrobots.txt により表示されません ? 詳細
インデックスはクロールとは全く異なる。簡単に言うと、URLはクロールされる前に、発見されなければならず、「インデックス」される前に(より正確に表現するなら、グーグルのインデックス内のワードに関連付ける)前にクロールされなければならない。
最近仲良くなったエンリコ・アルタヴィラは、次のように説明していた。私にはこれ以上分かりやすく説明することが出来ないため、引用させてもらう :
インデックスは、文書ではなく、ワードやフレーズのリストを持ち、その一つ一つに、当該のワードやフレーズに関連する全ての文書への参照情報が与えられている。
私達は「文書がインデックスされた」とよく言うが、実際には、「文書に関連するワードの一部が、文書に向けられるようになった」ことを意味する。文書は、そのままの状態で別の場所にアーカイブされている。
また、古くから付き合いがあり、グーグルに務めた経験を持つ ヴァネッサ・フォックスは、次のように説明している:
グーグルは、URLについて学び…その後、URLをクロールのスケジュールシステムに加える。リストを推測し、それから、優先度を考慮してURLのリストを再編成し、その順番通りにクロールしていく。
優先度は、様々な要因により左右される…ページのクロールが終わると、グーグルは、別のアルゴリズムのプロセスを実行し、インデックスに当該のページを保存するかどうかを決定する。
要するに、グーグルは、把握しているページを全てクロールするわけでも、クロールするページを全てインデックスしているわけでもないと言うことだ。
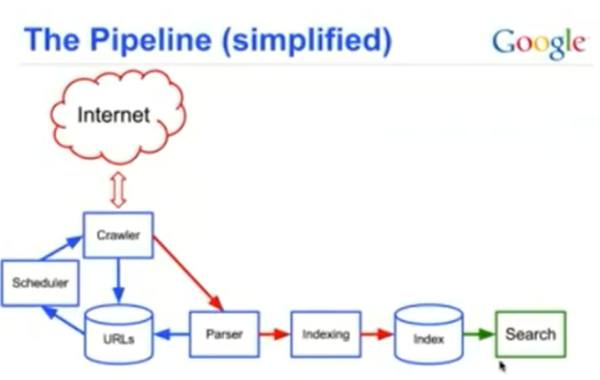
以下に、グーグルが提供したルート図を簡素化したものを掲載する:
その他にも幾つか注意してもらいたい点がある:
– robots.txtは、ページのクロールをブロックするだけである。そのため、グーグルは、上の例のようなページをたまに検索結果に表示する。内部リンク等のアイテムを基にページとワードを関連付けることが可能であっても、ページのコンテンツをクロールすることは出来なかったからだ。
– ページレベルのnoindexコマンドは、確定的ではない。グーグルはページをクロールして、ページ上のワードをインデックスと関連付けることが可能だが、検索結果に当該のページを盛り込むことを意図しているわけではない。
しかし、グーグルは、noindex処理したページを、誰でも見ることが出来る記録に含めることがある。実際に、グーグルは、その他のシグナルにより、インデックスされるべきだと判断される場合、noindexコマンドを無視することもあると明言している。これは、グーグルが、その他の検索エンジンとは一線を画する重要な領域である、ヤフー!とビングは、noindexのコマンドに従い、インデックスすることも、検索結果に盛り込むこともない。
また、カノニカル、パラメータの除外を含むその他の要素もまた、グーグルがページについて把握し、クロール/インデックスする間に処理されていく点も注目に値する。
次に理解してもらいたいのは、リンク、そして、リンクが処理される仕組みである。ここで最も重要なことは、リンク(そして、その延長線上にあるページランク)は、クロールの最中に処理されるわけではない点である。つまり、グーグルは、先ほど説明したようにクロールを行うものの、クロールを行う間は、ページランクの検討を行わずに、別の段階で対処しているのだ。
このポイントはどのような意味を持つのだろうか?
2012年8月20日に行われたウェブマスターハングアウトで、この点を指摘するためにグーグルが用いたスライドのスクリーンショットを以下に掲載する:
![]()
劣悪なリンクを処理する方法として、もう一つ挙げられるのが、リンクのソースを否認する方法でる。これは、グーグルが受け入れた場合、ソースリンクに「nofollow」を加えるのと同じ技術的な影響をもたらす。
これだけでは、検索エンジンの仕組みを完全に理解することは出来ないだろう。とりあえず、覚えてもらいたい重要な点を以下に挙げていく:
知らなかった情報はあっただろうか?私自身は、リンクのリファラーを.htaccessでブロックし、ページランクの流れを断ち切ることが出来ると(誤った)考えていた。皆さんにも、どのような誤った考えの下、SEOに取り組んでいたのか、振り返ってもらいたい。
事実確認作業に協力してくれた、エンリコ・アルタヴィラに感謝の意を伝えたい。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「How Search Engines Work ? Really!」を翻訳した内容です。
2002年設立から、20年以上に渡りSEOサービスを展開。支援会社は延べ2,000社を超える。SEO/CRO(コンバージョン最適化)を強みとするWebコンサルティング会社。日本初のSEO情報サイトであるSEO Japanを通じて、日本におけるSEOの普及に大きく貢献。
SEO最新情報やセミナー開催のお知らせなど、お役立ち情報を無料でお届けします。









